
`\pi` Day 2021 Art Posters - A forest of `\pi` (a Lindenmayer system)









On March 14th celebrate `\pi` Day. Hug `\pi`—find a way to do it.
For those who favour `\tau=2\pi` will have to postpone celebrations until July 26th. That's what you get for thinking that `\pi` is wrong. I sympathize with this position and have `\tau` day art too!
If you're not into details, you may opt to party on July 22nd, which is `\pi` approximation day (`\pi` ≈ 22/7). It's 20% more accurate that the official `\pi` day!
Finally, if you believe that `\pi = 3`, you should read why `\pi` is not equal to 3.

The trees along this city street,
Save for the traffic and the trains,
Would make a sound as thin and sweet
As trees in country lanes.
—Edna St. Vincent Millay (City Trees)
 buy artwork
buy artwork


Welcome to this year's celebration of `\pi` and mathematics.
The theme this year is flower and flowers—in contrast to last year's understandable downturn in mood.
This year's `\pi` poem City Trees by Edna St. Vincent Millay.
This year's `\pi` day song is Sway by Laleh.

The forest was generated using an Lindenmayer system — this part of the process is relatively easy.
Integrating variation into how the trees look while keeping a clean look-and-feel took a lot of experimentation — there are many free parameters in this section.
Lindenmayer system
A Lindenmayer system is a kind of parallel rewriting system. The system starts with some initial state, typically represented by a string. For example FX.
On each iteration, rules are applied to each characters in the state, which replaces the character with some other character. For example, suppose we replace X with [-FX][+FX]. Starting with the axiom FX The first three rounds of rewriting gives each give us
FX F[-FX][+FX] F[-F[-FX][+FX]][+F[-FX][+FX]] F[-F[-F[-FX][+FX]][+F[-FX][+FX]]][+F[-F[-FX][+FX]][+F[-FX][+FX]]]
It doesn't look like much, I know, but the magic happens when you interpret these characters in the context of turtle graphics. Specifically, let
F move forward distance d - turn left &theta degrees; + turn right &theta degrees; [ spawn a new turtle at this position facing at current angle ] restore previous turtle
If we set `\theta = 15\deg` then the shapes for each iteration are
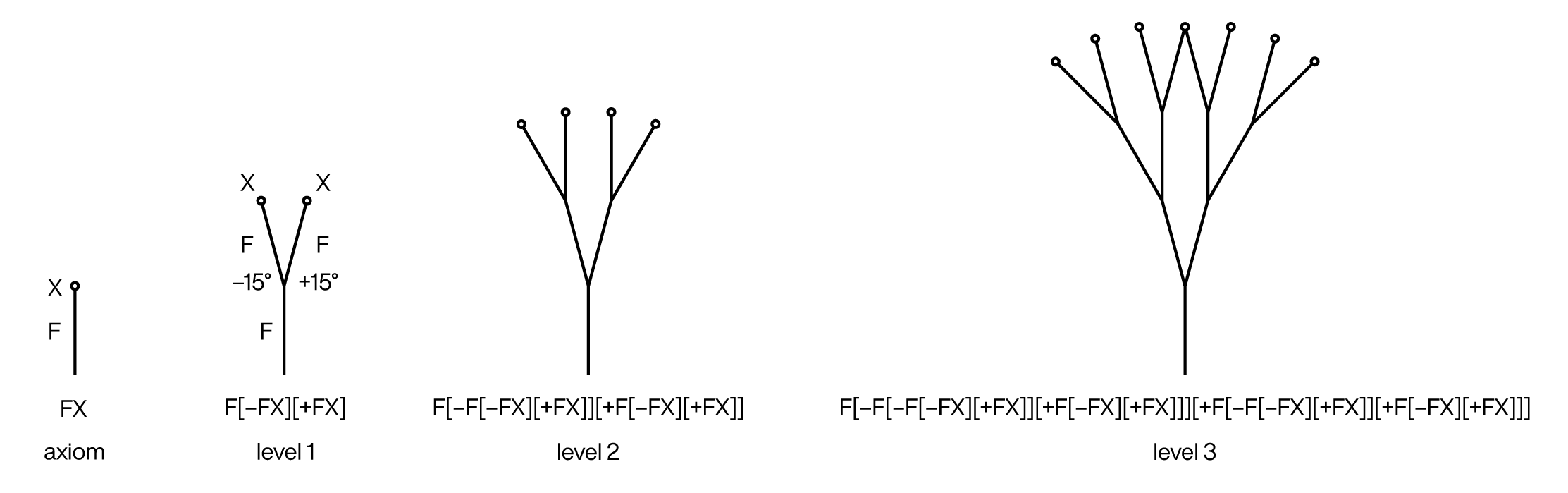
FX and rewrite rule X = [-FX][+FX].
We can interpret F as a branch and X a point were new branches grow. You can already see that by level 3 two of the branches — there's nothing in the system that prevents this, since each turtle operates independently.
Rules can be as simple or as complicated as you want and new characters to the string can be added to correspond to different turtle actions.
The `\pi` forest Lindenmayer system
The rules for the `\pi` forest are quite simple. The system starts with the axiom fX (grow a trunk and then branch off) and each digit corresponds to a different branching rule — the digit gives the number of branches with zero terminating a branch.
X 0 [] X 1 [---FX][++h] X 2 [----FX][+++FX] X 3 [-----FX][-FX][++++FX] X 4 [------FX][---FX][++FX][+++++FX] X 5 [-------FX][----FX][-FX][+++FX][+++++++FX] X 6 [--------FX][------FX][---FX][+FX][+++++FX][++++++++FX] X 7 [--------FX][-----FX][--FX][FX][+++FX][++++++FX][+++++++++FX] X 8 [---------FX][------FX][---FX][-FX][++FX][++++FX][+++++++FX][+++++++++FX]
where each – or + correspond to a left or right turn of 8 degrees. Any turns
The digit 9 has a special rule that sprouts a flower at the previous branching point and starts a new tree.
Also, at least step branches grow
F FF f ff g gg
with the f step being a fraction `(1-1/\pi)^2 \approx 46%` of the length of F and g being `(1-1/\pi)^4 \approx 22%` of the length of F. These shorter branch allow me to have a shorter trunk (axiom is fX and not FX) and a very short branch used in the rule for the digit 1, which branches off to one side while growing a little stubby branch to the other side.
There is one additional rule in which the turtle is mirrored at a branching point when a digit and the next digit have different parity (one odd and one even).
X = MX
The mirror operator makes the current turtle interpret any left turns as right turns, and vice versa.
The reason for the multiple turns in the rules is for convenience &mdsah; it allows me to define the angles of the branches as a multiple of a fixed value.
The system is grown for 6 iterations.
The first tree
Here is the first tree of the forest – for digits 314159. It ends in a 9 because the rule for 9 is to grow a flower, terminate the current tree and start a new tree with the next set of digits (up to the next 9, and so on).
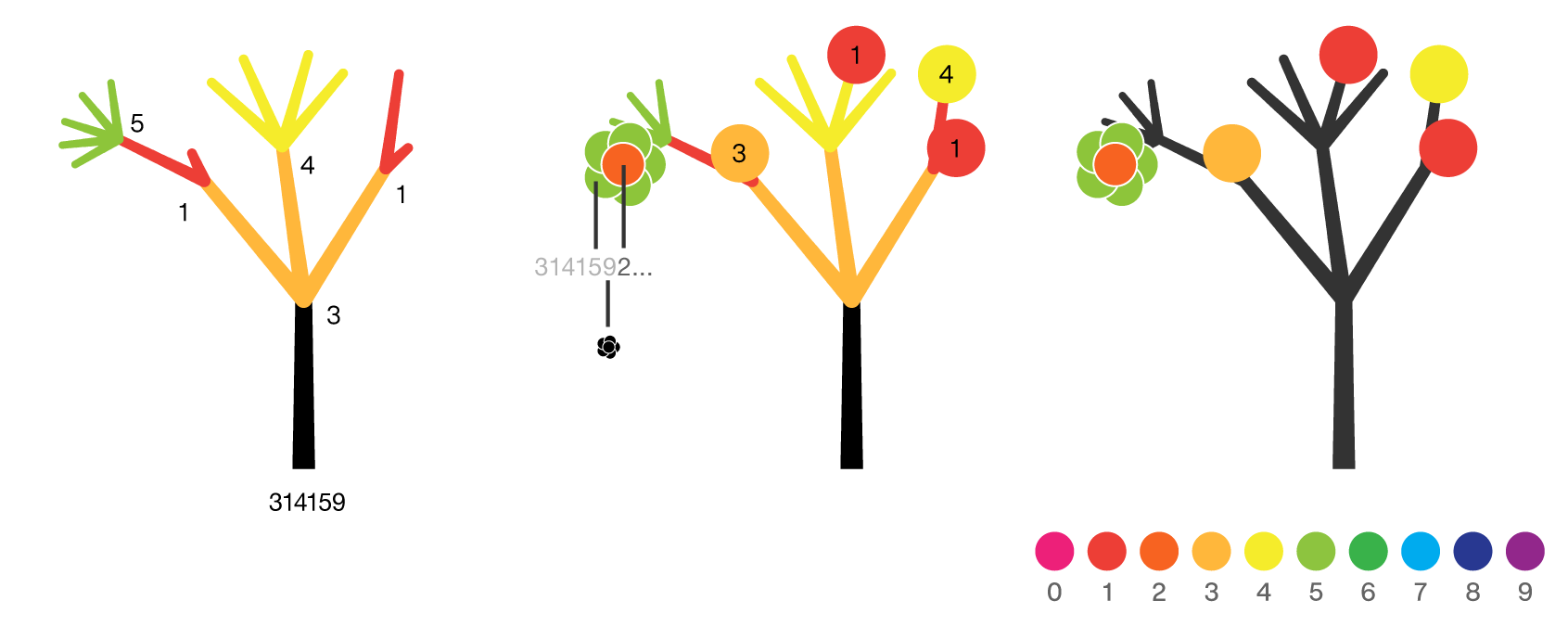
You can trace the digits for the tree left-to-right along the leaves. The flower of the 9 will appear on the branch of the digit immediately before it — in this case, a 5. The color of the flower petal is green (5) and the center is dark orange (first digit of the next tree).
The L-system string for this tree is below. See if you can discover what symbol is used for the flower.
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff [-----FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF [---FFFFFFFFFFFFFFFF [-------FFFFFFFFO][----FFFFFFFF][-FFFFFFFF][+++FFFFFFFF][+++++++FFFFFFFF] ] [++gggggggggggggggg] ] [-FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFM [------FFFFFFFFFFFFFFFF][---FFFFFFFFFFFFFFFF][++FFFFFFFFFFFFFFFF][+++++FFFFFFFFFFFFFFFF] ] [++++FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF [---FFFFFFFFFFFFFFFF][++gggggggggggggggg] ]
adding variation
To add variation to the tree, I take the tree's digits and create linear congruential generators for each of the following: branch turn angle, branch growth rate, thickness tapering and turtle angle when growing a branch.
Each generator is constructed as follows. The digits of the tree `d_1d_2d_3...d_n` are split into `a = d_1d_2d_3...d_{n-1}`, `c = d_n` and `m = d_1d_2d_3...d_n`. The generator is seeded with `X_0 = d_1` and then the next digit is `X_1 = (a X_0 + c) \; \textrm{mod} \; m`. Each output `X_i` is transformed to `y \times (2X_i/m - 1)`. Because some of the trees have a large number of digits, the operations are performed with an arbitrary precision library.
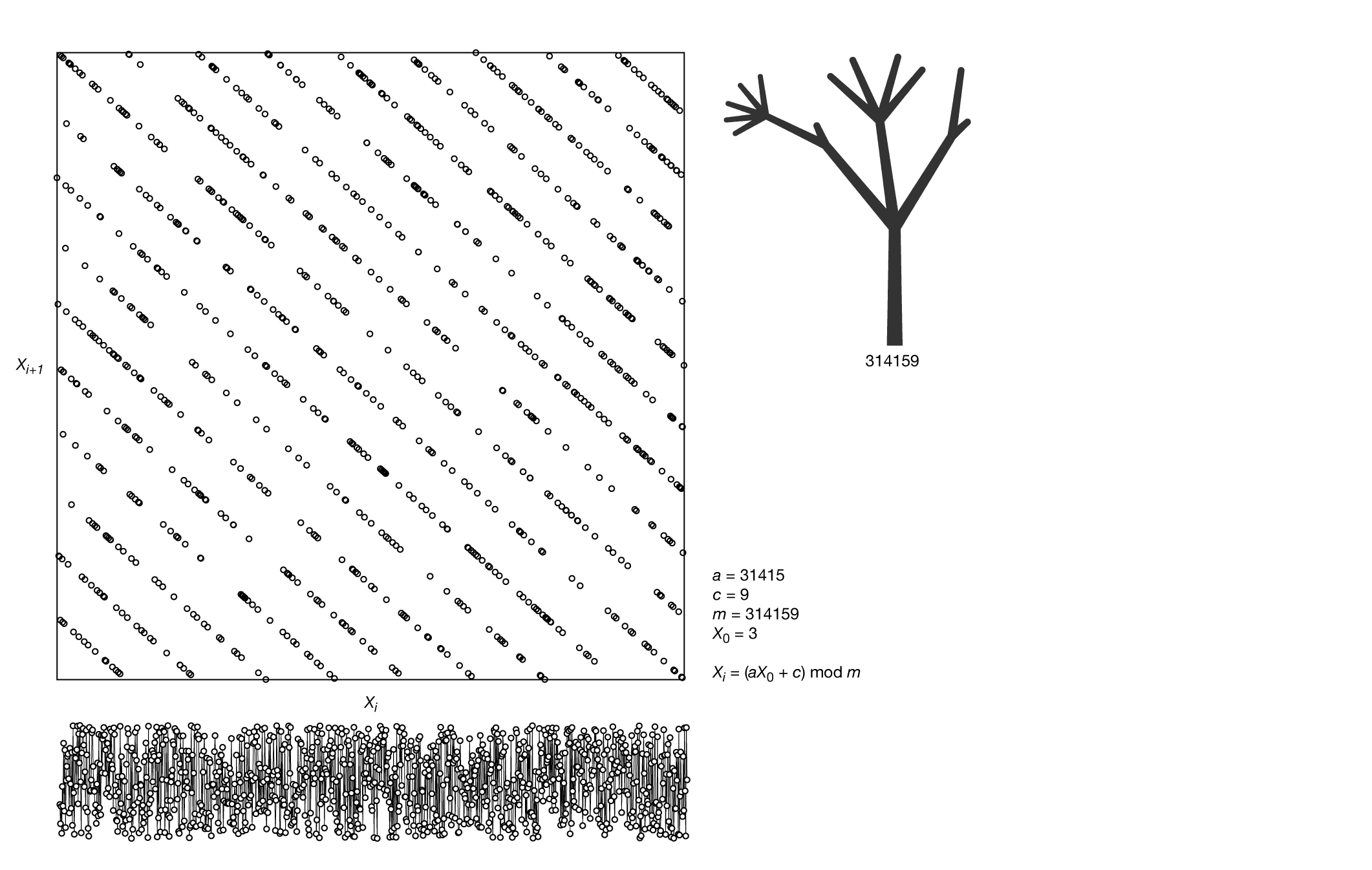
The output will be distributed in the range `[-y,y)`. The distribution will depend on the values of `a`, `c` and `m`. It might be reasonably uniform for some combinations and absolutely non-uniform for others. But here, non-uniform doesn't mean horrible — just another rule in the digit forest.
Each type of variation starts with an identical generator.
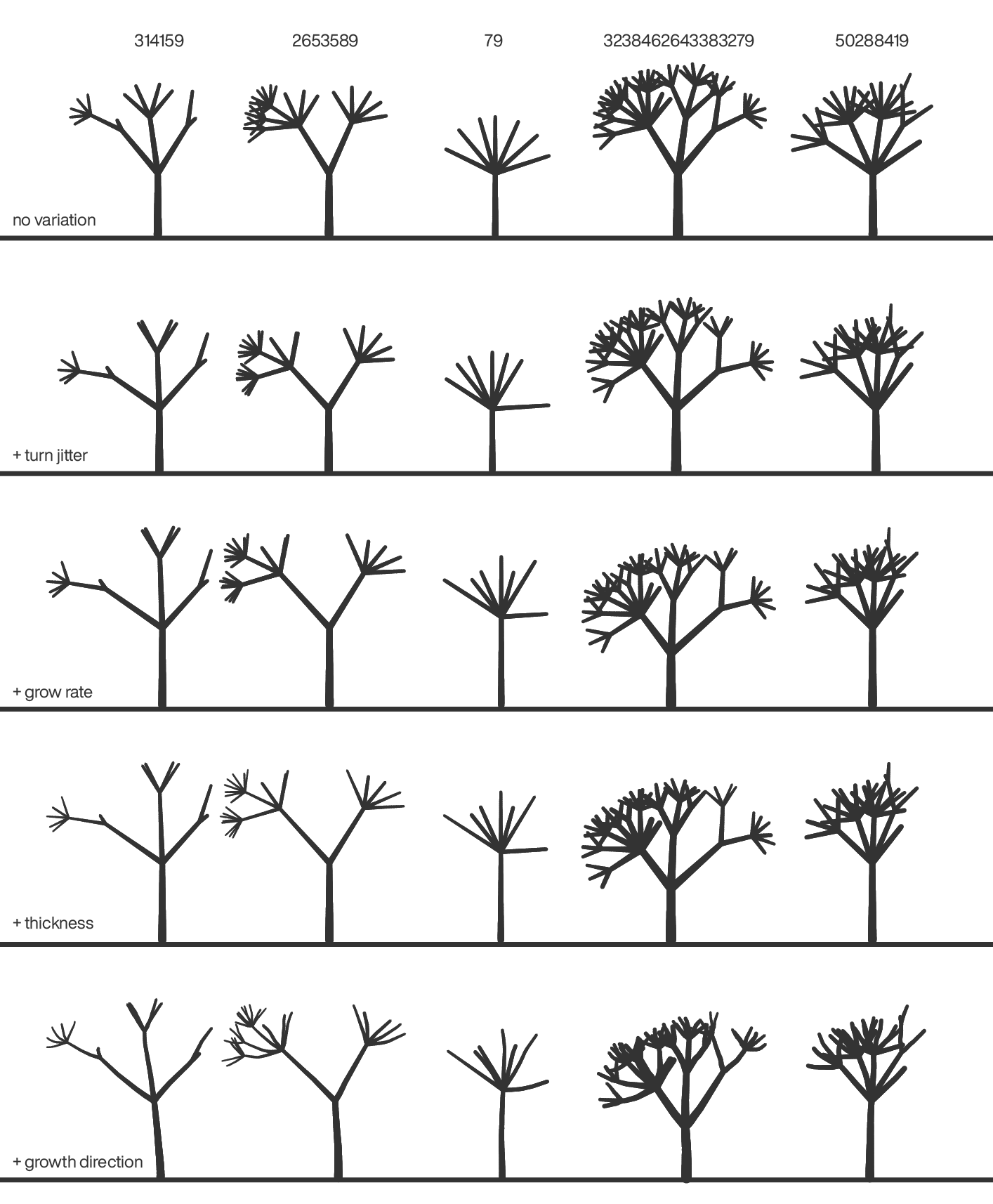
The parameters that influence the amount of variation are irrelevant — I tweaked them until I had something that looked "pretty good".
winds of change are blowing
You might have noticed that because a branch growth step is doubled at each iteration, a branch is composed of 64 turtle steps. This was done so that there's lots of opportunities to sample variation along a branch. And also for boring technical reasons: SVG does not allow a path with varying thickness.
This means that variation can build up along a branch, especially if we allow the turtle to veer quite a bit as the branch grows. Remember, a branch begins to grows in a particular direction but can change course along its growth.
Below I show what happens when I crank up every variation type by 200% and by 300% (e.g. 300% moar branch growth rate jitter!). Things add up pretty quickly — I'm looking at you 79! What are you doing? Who knew the digit forest could be so complicated?
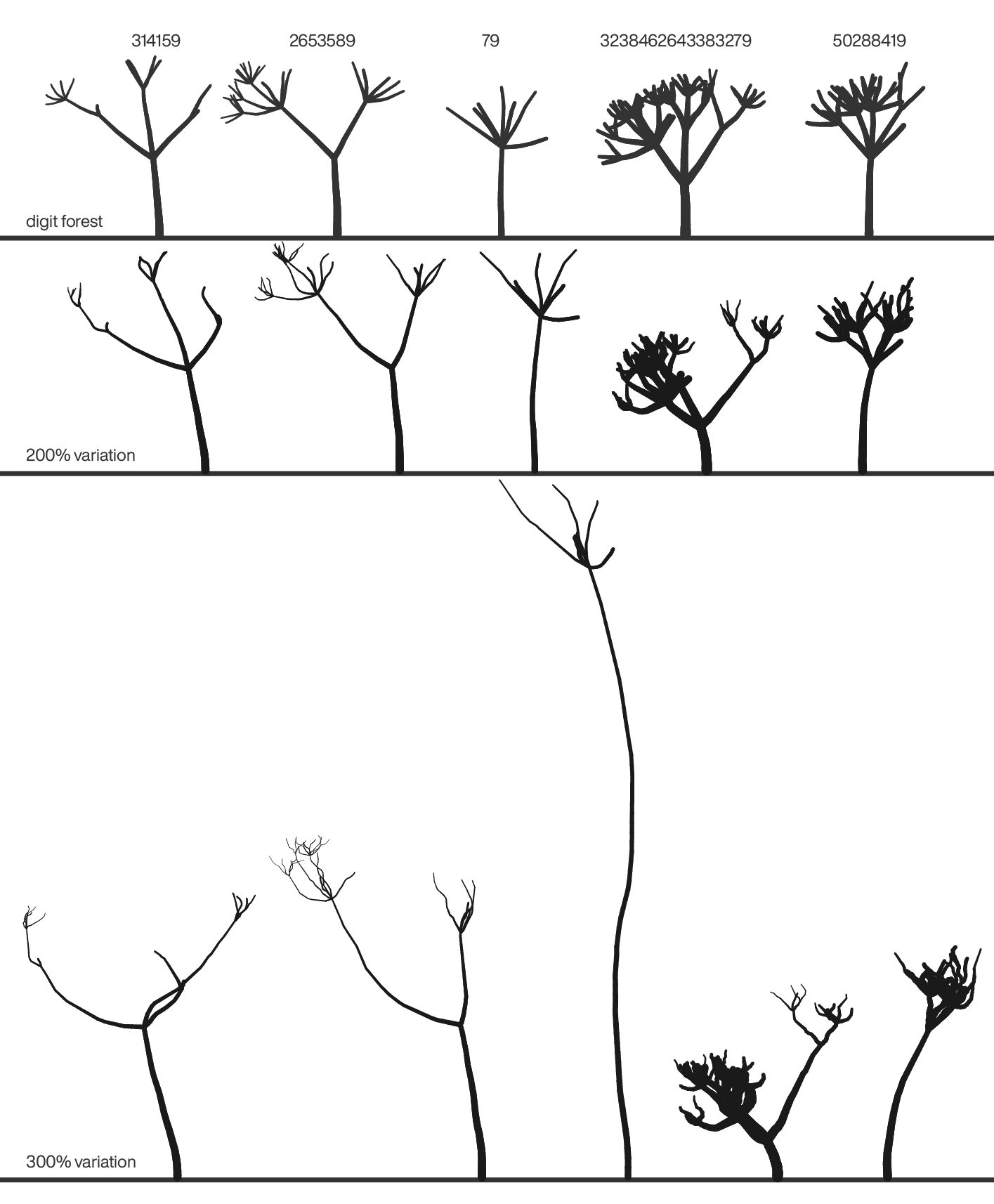
once more with ecosystem flavour
Exploring the space of variation is fun — even at 1am as I'm trying to finish this.
Below are some scenarios to get the imagination going.
The underwater scenario uses an effect in which turtle angle during branch growth is increased and constrained to be mostly up and no branch thickness change.
The prickly forest has a larger branch angle and larger branch length decay as a function of depth.
The dry forest has extreme thickness tapering and branch growth angle variation increases with each branch depth.
Finally, the bat cave is similar to the underwater case except that it has a much narrower branching angle and branch length now increases with branch depth. And one more change that's easy to spot.

So as you can see, the canonical digit forest is just one of a wide range of possible numerical environments.
Nasa to send our human genome discs to the Moon
We'd like to say a ‘cosmic hello’: mathematics, culture, palaeontology, art and science, and ... human genomes.



Comparing classifier performance with baselines
All animals are equal, but some animals are more equal than others. —George Orwell
This month, we will illustrate the importance of establishing a baseline performance level.
Baselines are typically generated independently for each dataset using very simple models. Their role is to set the minimum level of acceptable performance and help with comparing relative improvements in performance of other models.
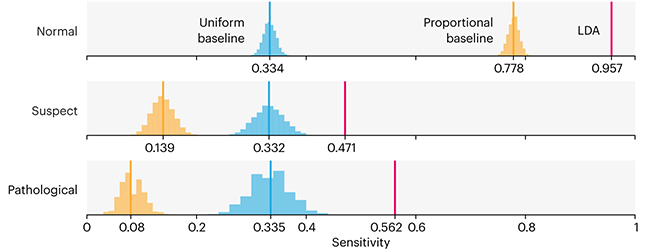
Unfortunately, baselines are often overlooked and, in the presence of a class imbalance5, must be established with care.
Megahed, F.M, Chen, Y-J., Jones-Farmer, A., Rigdon, S.E., Krzywinski, M. & Altman, N. (2024) Points of significance: Comparing classifier performance with baselines. Nat. Methods 20.
Happy 2024 π Day—
sunflowers ho!
Celebrate π Day (March 14th) and dig into the digit garden. Let's grow something.
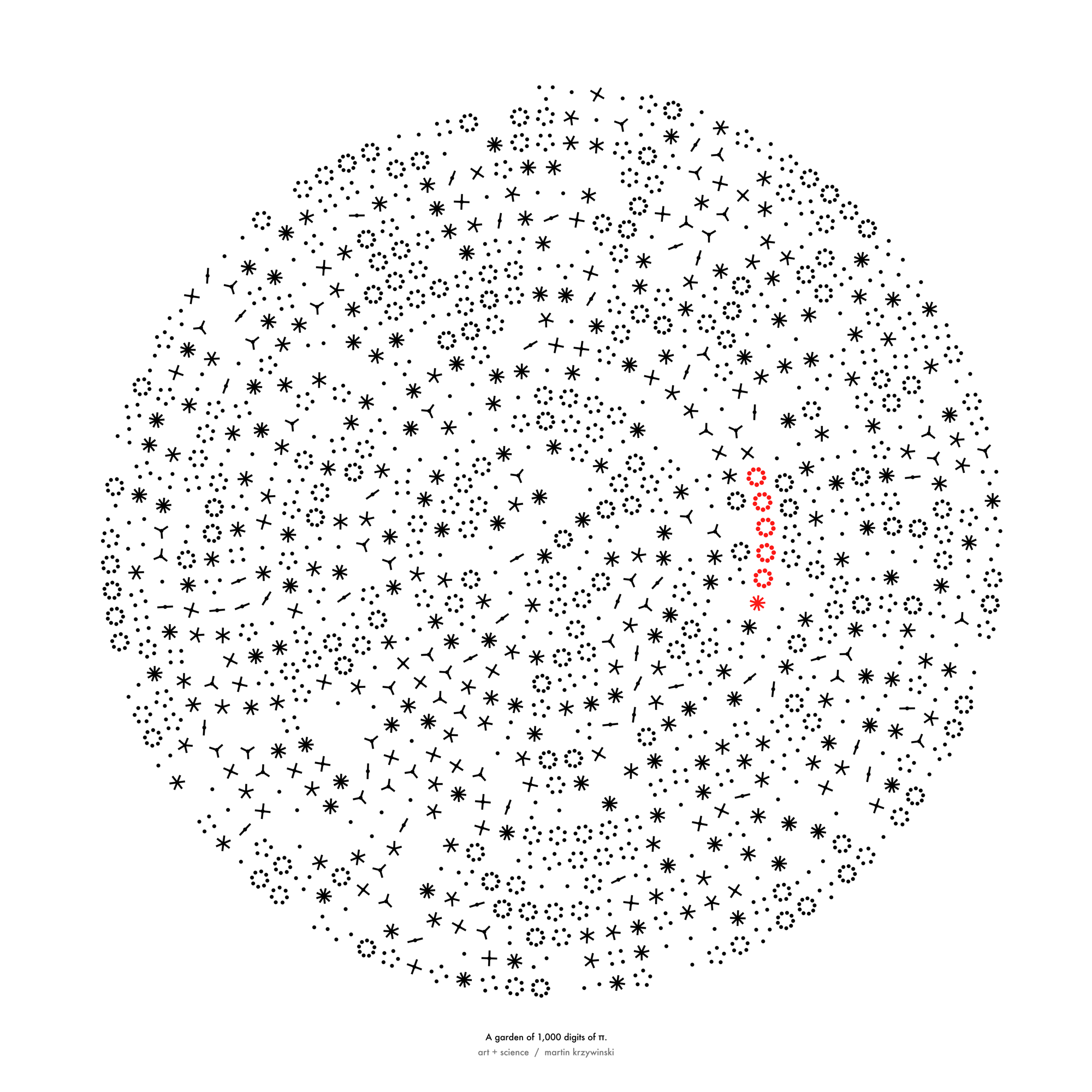
How Analyzing Cosmic Nothing Might Explain Everything
Huge empty areas of the universe called voids could help solve the greatest mysteries in the cosmos.
My graphic accompanying How Analyzing Cosmic Nothing Might Explain Everything in the January 2024 issue of Scientific American depicts the entire Universe in a two-page spread — full of nothing.
The graphic uses the latest data from SDSS 12 and is an update to my Superclusters and Voids poster.
Michael Lemonick (editor) explains on the graphic:
“Regions of relatively empty space called cosmic voids are everywhere in the universe, and scientists believe studying their size, shape and spread across the cosmos could help them understand dark matter, dark energy and other big mysteries.
To use voids in this way, astronomers must map these regions in detail—a project that is just beginning.
Shown here are voids discovered by the Sloan Digital Sky Survey (SDSS), along with a selection of 16 previously named voids. Scientists expect voids to be evenly distributed throughout space—the lack of voids in some regions on the globe simply reflects SDSS’s sky coverage.”
voids
Sofia Contarini, Alice Pisani, Nico Hamaus, Federico Marulli Lauro Moscardini & Marco Baldi (2023) Cosmological Constraints from the BOSS DR12 Void Size Function Astrophysical Journal 953:46.
Nico Hamaus, Alice Pisani, Jin-Ah Choi, Guilhem Lavaux, Benjamin D. Wandelt & Jochen Weller (2020) Journal of Cosmology and Astroparticle Physics 2020:023.
Sloan Digital Sky Survey Data Release 12
Alan MacRobert (Sky & Telescope), Paulina Rowicka/Martin Krzywinski (revisions & Microscopium)
Hoffleit & Warren Jr. (1991) The Bright Star Catalog, 5th Revised Edition (Preliminary Version).
H0 = 67.4 km/(Mpc·s), Ωm = 0.315, Ωv = 0.685. Planck collaboration Planck 2018 results. VI. Cosmological parameters (2018).
constellation figures
stars
cosmology
Error in predictor variables
It is the mark of an educated mind to rest satisfied with the degree of precision that the nature of the subject admits and not to seek exactness where only an approximation is possible. —Aristotle
In regression, the predictors are (typically) assumed to have known values that are measured without error.
Practically, however, predictors are often measured with error. This has a profound (but predictable) effect on the estimates of relationships among variables – the so-called “error in variables” problem.
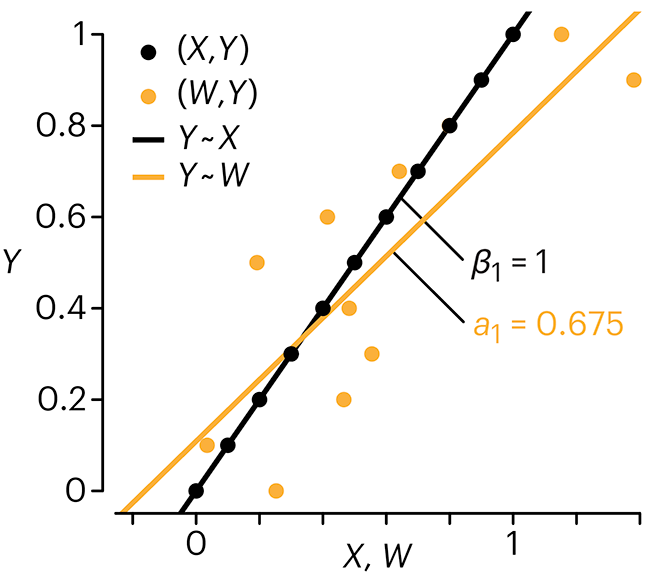
Error in measuring the predictors is often ignored. In this column, we discuss when ignoring this error is harmless and when it can lead to large bias that can leads us to miss important effects.
Altman, N. & Krzywinski, M. (2024) Points of significance: Error in predictor variables. Nat. Methods 20.
Background reading
Altman, N. & Krzywinski, M. (2015) Points of significance: Simple linear regression. Nat. Methods 12:999–1000.
Lever, J., Krzywinski, M. & Altman, N. (2016) Points of significance: Logistic regression. Nat. Methods 13:541–542 (2016).
Das, K., Krzywinski, M. & Altman, N. (2019) Points of significance: Quantile regression. Nat. Methods 16:451–452.
Convolutional neural networks
Nature uses only the longest threads to weave her patterns, so that each small piece of her fabric reveals the organization of the entire tapestry. – Richard Feynman
Following up on our Neural network primer column, this month we explore a different kind of network architecture: a convolutional network.
The convolutional network replaces the hidden layer of a fully connected network (FCN) with one or more filters (a kind of neuron that looks at the input within a narrow window).
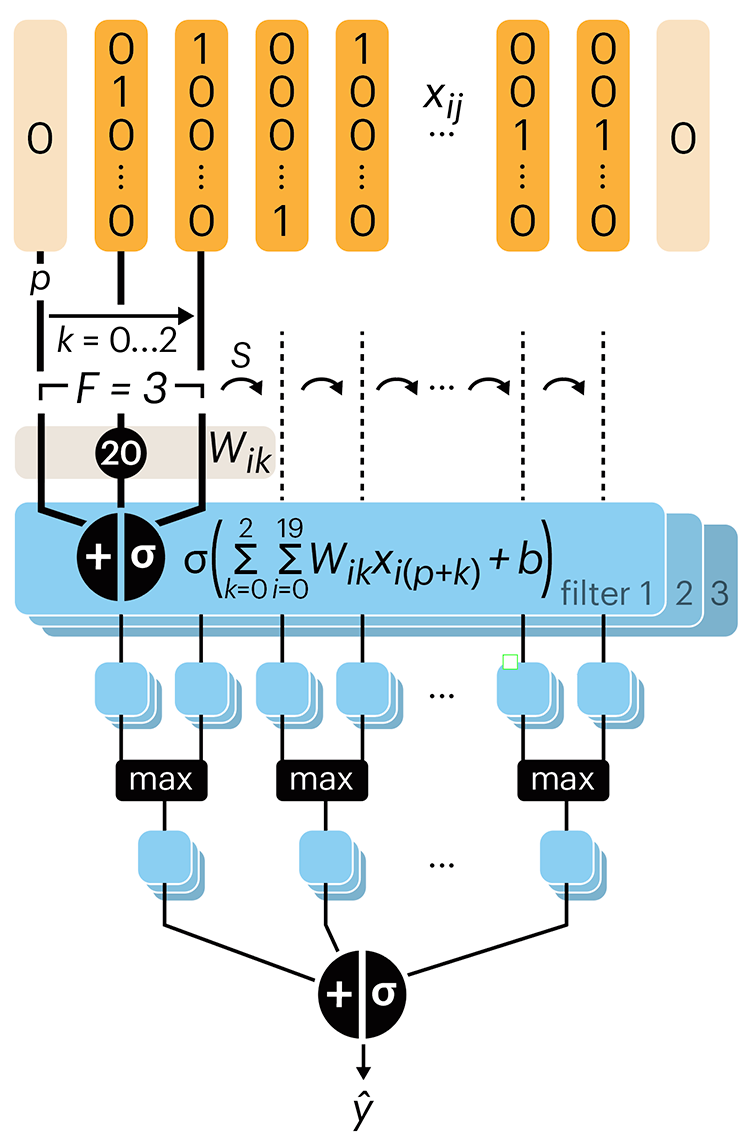
Even through convolutional networks have far fewer neurons that an FCN, they can perform substantially better for certain kinds of problems, such as sequence motif detection.
Derry, A., Krzywinski, M & Altman, N. (2023) Points of significance: Convolutional neural networks. Nature Methods 20:1269–1270.
Background reading
Derry, A., Krzywinski, M. & Altman, N. (2023) Points of significance: Neural network primer. Nature Methods 20:165–167.
Lever, J., Krzywinski, M. & Altman, N. (2016) Points of significance: Logistic regression. Nature Methods 13:541–542.