



Essentials of Data Visualization — 8-part miniseries
Thinking about drawing data and communicating science
This video series focuses on relevant and practical concepts in scientific data visualization. My aim is to make you think more clearly about visual presentation and to make you a better communicator. Each video is about 15 minutes long and comes with a slide deck of the images used in the video, exercise and suggested solutions.
Each video in the series presents fundamental ideas and is designed to provide constraints and guidance to your thoughts about communicating your data. The purpose of scientific data visualization is not merely to inform but also to answer and generate hypotheses.
Whatever your communication medium, you should always have consistency (good!), redundancy (bad!) and an appropriate mapping between relevant and salience in mind (tricky!). Once these are satisfied, look to flow and density of material to achieve clarity (elusive!).
I present these essential topics using biological data as examples. But if you're not a biologist, don't worry. Instead, think about the data structure rather than meaning and you'll be fine.
Download all course materials.
1. Data Encoding

Make it easy to answer relevant questions.
When you think of data visualization, the first ideas that come to mind are a scatter plot, or a bar char, a box plot or a network diagram. These are all data encodings—methods that relate data values to the positions, sizes and shapes of the lines or symbols that appear on the screen or in a figure. There are many data encodings—which do you choose?
watch | PDF slides
2. Shapes and Symbols

Intuitively encode role and relevance.
Shapes and glyphs are really important. They make up the heart of a lot of data plots. Your default should be the circle. If you need different shapes, try to map the classes as intuitively as possible onto the shapes. Use less prominent symbols for data that are less relevant (such as reference data included for context).
watch | PDF slides
3. Color

Use it for emphasis and visual separation.
Color is one of the most exciting ways in which you can completely screw over your visualization. What can start off as a great diagram can be absolutely ruined by a lack of color judgment. When using color, ask yourself—do I need it? Try to work around it using grey tones from Brewer palettes. If you succeed, you’re in a perfect place to use spot color, sparingly, for emphasis.
watch | PDF slides
4. Uncertainty

Don't make errors in error bars.
Knowing the limits of your knowledge is very important. In biology, it’s important to be able to sample the extent of biological variation. And so being able to show this and other forms of variation in measurements or any computed values in visualizations is very important—it addresses reproducibility and your capacity to make statistical inference. Often this is done with error bars. Ironically, there’s a lot of error associated with the use of and interpretation of error bars.
watch | PDF slides
5. Design

Organize and clarify.
Design plays a large role in data visualization. Think of design as choreography for the page. In our context it’s not merely driven by aesthetic, but function. Although there’s always room for aesthetic—gently applied—and I really encourage you to find your own and continue to refine it. But always remember, be understood before being articulate. Be legible before being attractive! Your goal here isn’t to make inroads on the global stage of aesthetic studies. Become a good visual explainer. It’s harder … and more worth doing.
watch | PDF slides
6. Nothing

No data, no ink.
Data-to-ink ratio, taken to the extreme: if there is no data to show, no ink should be used. The idea of “no data to show” may correspond to a variety of scenarios. There may be sincerely no data to show—no values were collected. Or, there are no significant changes to see. Where possible, you should use empty space to indicate lack of data or lack of change in data. You should never be distracted by something that isn’t relevant and empty space is not distracting—it really just provides contrast to adjacent elements, which presumably correspond to actual data or actionable data.
watch | PDF slides
7. Labels

Respect type and use it to establish hierarchy.
Open up a journal or your favourite text book. Find a figure. There’s probably some labels in there. Maybe it’s a multi-panel figure and the labels are the titles. Maybe there are some callouts that tell you what the parts are. If it’s a plot there are probably axis labels and tick labels and maybe a legend with some labels. There’s usually several informational layers in the image, each with their own labels. These labels should reflect that these layers are different. They should also reflect the relative importance of these layers.
watch | PDF slides
8. Process

Creating a visualization for Scientific American Graphic Science: from start to finish.
Let’s now look at the process of designing a visualization from scratch—from the encoding all the way to design. This was a graphic I did for the June 2015 issue of Scientific American. It appeared on the Graphic Science page.
watch | PDF slides
Propensity score weighting
It is not certain that everything is uncertain. —Blaise Pascal
We have already explored how we can mitigate bias caused by confounding variables in observational studies using propensity score (PS) matching (PSM) and propensity score weighting (PSW). However, any statistical model is only as good as its assumptions and, if it is specified incorrectly, it can itself produce biased estimates of the treatment effect.
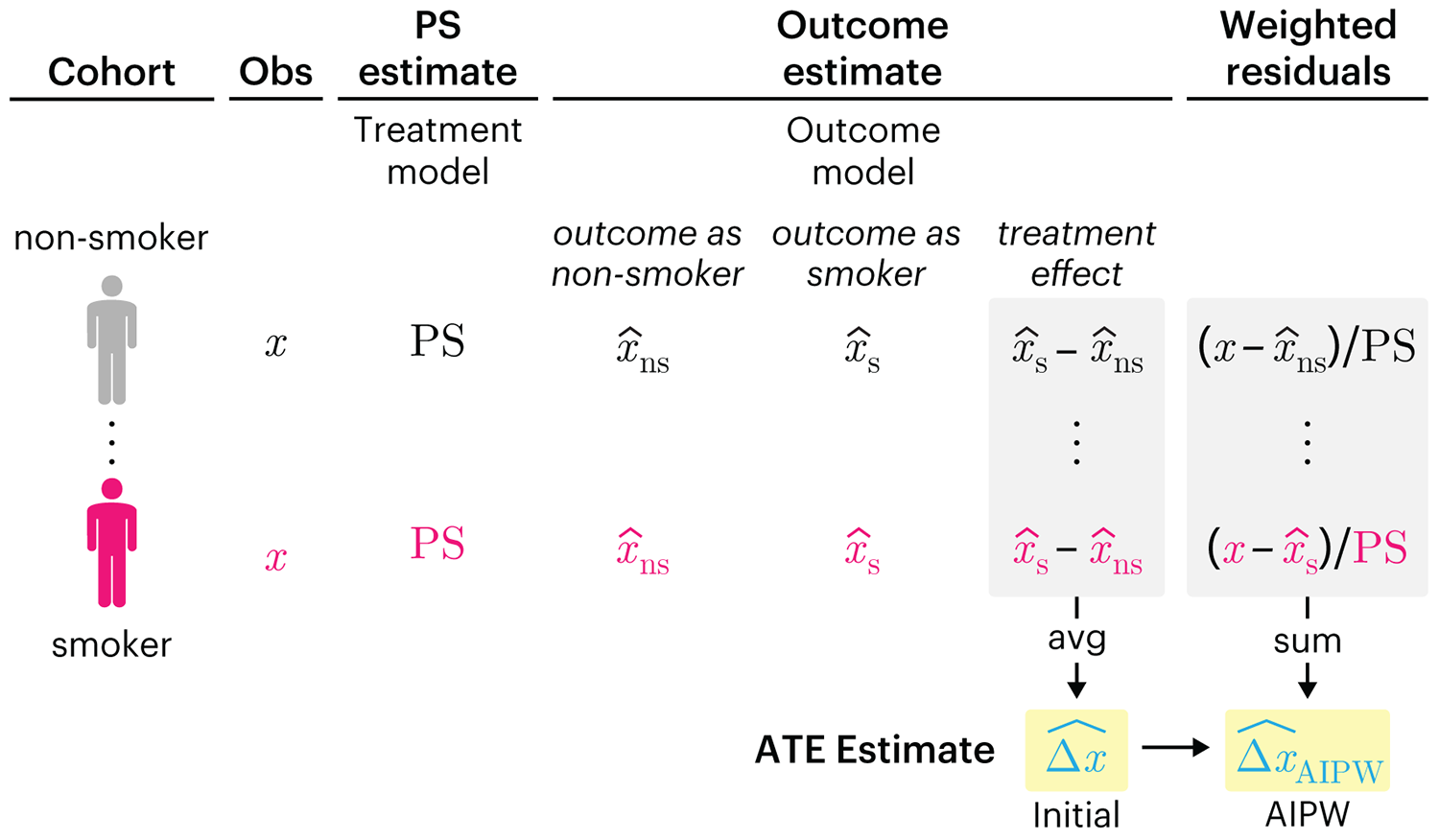
This month, we explore double robustness, a powerful statistical concept that provides a valuable “safety net” against the risk of an incorrect model. It offers two opportunities, instead of just one, to obtain a valid estimate of the treatment effect — making it possible to draw credible causal inferences from observational data without having to depend on a single set of modeling assumptions.
Kurz, C.F., Krzywinski, M. & Altman, N. (2026) Points of significance: Double Robustness. Nat. Methods 23:868–869.
Nature Biotechnology cover
My cover design on the 7 April 2026 Nature Biotechnology issue shows the dendrogram that represents a cluster of uniquely expressed (or downregulated) genes in human naive stem cells induced from such cells. Within each dendrogram block, the genomic barcode sequence (sampled from Supplementary Table 1) is depicted with a Code 39 barcode. The highlighted barcode is one of those used for cell isolation.
Ishiguro S. et al. A multi-kingdom genetic barcoding system for precise clone isolation (2026) Nature Biotechnology 44:616–629.

Browse my gallery of cover designs.

Happy 2026 π Day—
Art for the 5%
Celebrate π Day (March 14th) and enjoy the art — but only if you're part of the 5%.
Go ahead, see what you can't see.

Ishihara's Tests for Colour Deficiency
Authentic and accurate images of Ishihara's test plates photographed (and lovingly color-corrected) from the 38-plate Ishihara's Tests for Colour Deficiency.
I also provide the position, size, and color of each circle on each test plate.


Symmetric alternatives to the ordinary least squares regression
What immortal hand or eye, could frame thy fearful symmetry? — William Blake, "The Tyger"
This month, we look at symmetric regression, which, unlike simple linear regression, it is reversible — remaining unaltered when the variables are swapped.
Simple linear regression can summarize the linear relationship between two variables `X` and `Y` — for example, when `Y` is considered the response (dependent) and `X` the predictor (independent) variable.
However, there are times when we are not interested (or able) to distinguish between dependent and independent variables — either because they have the same importance or the same role. This is where symmetric regression can help.

Luca Greco, George Luta, Martin Krzywinski & Naomi Altman (2025) Points of significance: Symmetric alternatives to the ordinary least squares regression. Nat. Methods 22:1610–1612.