
Dummer - Like Nothing Else / A Hummer Satire
The Dummer project might give you the impression that I don't like Hummers. You'd be right.

The project was well received by The New York Times and very poorly by someone who felt sending me hate mail was a good idea. It was — I loved it.
Other Hummer satires include fuh2.com — there's some hope for us all.
The World's Most Popular Questions
What are the world's most popular questions? After all, what we know defines us as much as what we ask. So, let's look at who we are.
Using Google's autocomplete feature, which suggests the most similar searches to the one you have entered, I maintain a real-time compilation of the most common questions asked by millions of worldwide internet users.
This project (a) yields insight into the zeitgeist and (b) scares me. My reason for fright are questions such as these:
General Issues
How do people do extreme couponing?
Why can't I hold all these limes?
Why do I always feel like murdering everyone?
What's up with the World
Is the world really flat?
is the world being controlled by aliens?
Limits & Desires
What happens if I make a formal commitment to Satan?
Love & Heart
Why is my boyfriend so insecure?
Why is my girlfriend so emotional?
Health
My head is full of pretty lumps.
Pain & Suffering
my elbow is dark and dry
why do I continue to hit myself with a hammer?
when does my head stop growing?
Sizes & Extremes
Who is the most powerful Jedi?
Where is the hardest part of your head?
Religion & Faith
Can Jesus microwave a burrito?
Can I pray with my eyes open?
Should I pray for a husband?
Neologisms - New Words, Much Needed
I like words. The pleasure of effectively using acerebral and defenestrate in the same sentence cannot be understated.
On occassion I found myself in a situation where no word fit, existing or that I know about. Instead of rushing to the dictionary, I decided to make up my own, such as inconversible (a statement without a logical converse), mystific (unexplainably wonderful), postpetizer (course ordered after dessert), prenopsis (a summary of something formulated before it was experienced), suscitate (breathe life into, for the first time), and others.
The current list of my neologisms is circos plot, compure, culturally inconversible, dependers, ee spammings, existangsty, fezday, hilbertonian, hive panel, hive plot, inconversible, metaomome, mystific, naytheism, naytheist, nes, neuroterror, neuroterrorism, newgrade, noward, nonposter, oldgrade, omome, omeomics, omicsophy, over, piddle, port knocking, postpetizer, pregratulate, prekfast, prenopsis, prepetizer, quinty, ratio hive, spammings, suscitate, unappropriate .
HDTR: High Dynamic Time Range Photography - Visualizing the Flow of Time
The HDTR method is a new approach to depicting the passage of time. High Dynamic Time Range (HDTR) images and are a composite of many photos taken over a long period of time, such as a day or even longer. Each part of the HDTR image is sampled from a different photo, either by column or row.
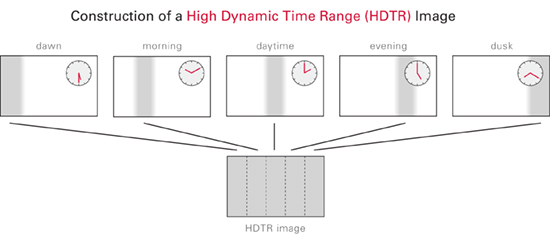
For example, the left part of the HDTR image might show the scene from 7am and the very right from 8pm, capturing the variation in light across an entire day.

Propensity score weighting
It is not certain that everything is uncertain. —Blaise Pascal
We have already explored how we can mitigate bias caused by confounding variables in observational studies using propensity score (PS) matching (PSM) and propensity score weighting (PSW). However, any statistical model is only as good as its assumptions and, if it is specified incorrectly, it can itself produce biased estimates of the treatment effect.
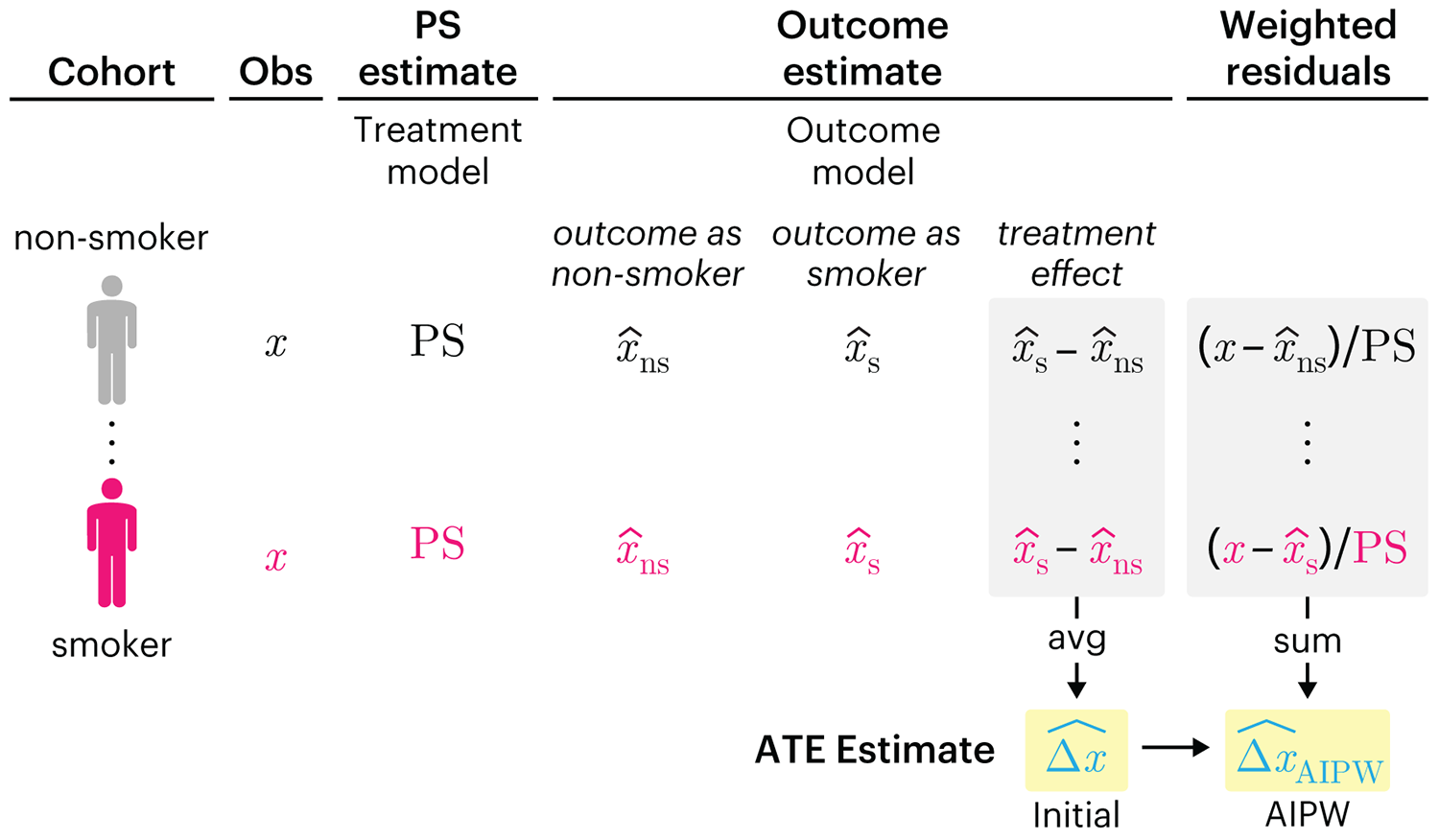
This month, we explore double robustness, a powerful statistical concept that provides a valuable “safety net” against the risk of an incorrect model. It offers two opportunities, instead of just one, to obtain a valid estimate of the treatment effect — making it possible to draw credible causal inferences from observational data without having to depend on a single set of modeling assumptions.
Kurz, C.F., Krzywinski, M. & Altman, N. (2026) Points of significance: Double Robustness. Nat. Methods 23:868–869.
Nature Biotechnology cover
My cover design on the 7 April 2026 Nature Biotechnology issue shows the dendrogram that represents a cluster of uniquely expressed (or downregulated) genes in human naive stem cells induced from such cells. Within each dendrogram block, the genomic barcode sequence (sampled from Supplementary Table 1) is depicted with a Code 39 barcode. The highlighted barcode is one of those used for cell isolation.
Ishiguro S. et al. A multi-kingdom genetic barcoding system for precise clone isolation (2026) Nature Biotechnology 44:616–629.

Browse my gallery of cover designs.

Happy 2026 π Day—
Art for the 5%
Celebrate π Day (March 14th) and enjoy the art — but only if you're part of the 5%.
Go ahead, see what you can't see.

Ishihara's Tests for Colour Deficiency
Authentic and accurate images of Ishihara's test plates photographed (and lovingly color-corrected) from the 38-plate Ishihara's Tests for Colour Deficiency.
I also provide the position, size, and color of each circle on each test plate.


Symmetric alternatives to the ordinary least squares regression
What immortal hand or eye, could frame thy fearful symmetry? — William Blake, "The Tyger"
This month, we look at symmetric regression, which, unlike simple linear regression, it is reversible — remaining unaltered when the variables are swapped.
Simple linear regression can summarize the linear relationship between two variables `X` and `Y` — for example, when `Y` is considered the response (dependent) and `X` the predictor (independent) variable.
However, there are times when we are not interested (or able) to distinguish between dependent and independent variables — either because they have the same importance or the same role. This is where symmetric regression can help.

Luca Greco, George Luta, Martin Krzywinski & Naomi Altman (2025) Points of significance: Symmetric alternatives to the ordinary least squares regression. Nat. Methods 22:1610–1612.
Beyond Belief Campaign BRCA Art
Fuelled by philanthropy, findings into the workings of BRCA1 and BRCA2 genes have led to groundbreaking research and lifesaving innovations to care for families facing cancer.
This set of 100 one-of-a-kind prints explore the structure of these genes. Each artwork is unique — if you put them all together, you get the full sequence of the BRCA1 and BRCA2 proteins.
