science + genomics
What if we were to print what we sequence?
Expressing the amount of sequence in the human genome in terms of the number of printed pages has been done before. At the Broad Institute, all of the human reference genome is printed in bound volumes.
At our sequencing facility, we sequence about 1 terabases per day. This is equivalent to 167 diploid human genomes (167 × 6 gigabases). The sequencing is done using a pool of 13 Illumina HiSeq 2500 sequencers, of which about 50% are sequencing at any given time.

This sequencing is extremely fast.
To understand just how fast this is, consider printing this amount of sequence using a modern office laser printer. Let's pick the HP P3015n which costs about $400—a cheap and fast network printer. It can print at about 40 pages per minute.
If we print the sequence at 6pt Courier using 0.25" margins, each 8.5" × 11" page will accomodate 18,126 bases. I chose this font size because it's reasonably legible. To print 1 terabases we need `10^12 / 18126 = 55.2` million pages.
If we print continuously at 40 pages per minute, we need `10^12 / (18126*40*1440) = 957.8` days.
If we had 958 printers working around the clock, we could print everything we sequence and not fall behind. This does not account for time required to replenish toner or paper.
what's cheaper, sequencing or printing?
It costs us about $12,000 to sequence a terabase in reagents. If we do it on a cost-recovery basis, it is about twice that, to include labor and storage. Let's say $25,000 per terabase.
Coincidentally, this is about $150 per 1× coverage of a diploid human genome. The cost of sequencing a single genome would be significantly higher because of overhead. To overcome gaps in coverage and to be sensitive to alleles in heterogenous samples, sequencing should be done to 30× or more. For example, we sequence cancer genomes at over 100×. For theory and review see Aspects of coverage in medical DNA sequencing by Wendl et al. and Sequencing depth and coverage: key considerations in genomic analyses by Sims et al.. (Thanks to Nicolas Robine for pointing out that redundant coverage should be mentioned here).
Printing is 44× more expensive than sequencing, per base: 25 n$ vs 1.1 μ$.
I should mention that the cost of analyzing the sequenced genome should be considered—this step is always the much more expensive one. In The $1,000 genome, the $100,000 analysis? Mardis asks "If our efforts to improve the human reference sequence quality, variation, and annotation are successful, how do we avoid the pitfall of having cheap human genome resequencing but complex and expensive manual analysis to make clinical sense out of the data?"
The cost of a single printed page (toner, power, etc) is about $0.02–0.05, depending on the printer. Let's be generous and say it's $0.02. To print 55.2 million pages would cost us $1.1M. This is about 44 times as expensive as sequencing.

Think about this. It's 44× more expensive to merely print a letter on a page than it is to determine it from the DNA of a cell. In other words, to go from the physical molecule to a bit state on a disk is much cheaper than from a bit state on a disk to a representation of the letter on a page.
Per base, our sequencing costs `$25000/10^12 = $25*10^-9`, or 25 nanodollars. At $0.02 and 18,126 bp per page, printing costs `0.02/18126 = $1.1*10^-6` or 1.1 microdollars.
If at this point you're thinking that printing isn't practical, the fact that the pages would weigh 248,000 kg and stack to 5.5 km should cinch the argument.
The capital cost of sequencing is, of course, much higher. The printers themselves would cost about $400,000 to purchase. The 6 sequencers, on the other hand, cost about $3,600,000.
sequencing is as fast as downloading
We sequence at a rate close to the average internet bandwidth available to the public.
At 3.86 Mb/s, we could download a terabase of compressed sequence in a day, assuming the sequence can be compressed by a factor of 3. This level of compression is reasonable—the current human assembly is 938 Mb zipped).
In other words, you would have to be downloading essentially continuously to keep up with our sequencing.
Nasa to send our human genome discs to the Moon
We'd like to say a ‘cosmic hello’: mathematics, culture, palaeontology, art and science, and ... human genomes.



Comparing classifier performance with baselines
All animals are equal, but some animals are more equal than others. —George Orwell
This month, we will illustrate the importance of establishing a baseline performance level.
Baselines are typically generated independently for each dataset using very simple models. Their role is to set the minimum level of acceptable performance and help with comparing relative improvements in performance of other models.
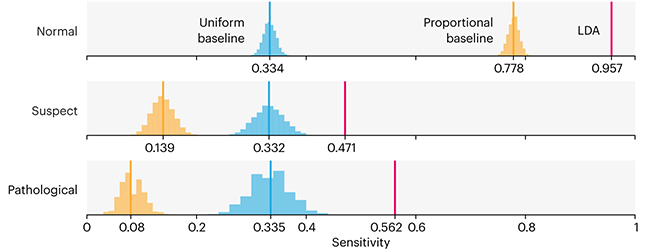
Unfortunately, baselines are often overlooked and, in the presence of a class imbalance5, must be established with care.
Megahed, F.M, Chen, Y-J., Jones-Farmer, A., Rigdon, S.E., Krzywinski, M. & Altman, N. (2024) Points of significance: Comparing classifier performance with baselines. Nat. Methods 20.
Happy 2024 π Day—
sunflowers ho!
Celebrate π Day (March 14th) and dig into the digit garden. Let's grow something.
How Analyzing Cosmic Nothing Might Explain Everything
Huge empty areas of the universe called voids could help solve the greatest mysteries in the cosmos.
My graphic accompanying How Analyzing Cosmic Nothing Might Explain Everything in the January 2024 issue of Scientific American depicts the entire Universe in a two-page spread — full of nothing.
The graphic uses the latest data from SDSS 12 and is an update to my Superclusters and Voids poster.
Michael Lemonick (editor) explains on the graphic:
“Regions of relatively empty space called cosmic voids are everywhere in the universe, and scientists believe studying their size, shape and spread across the cosmos could help them understand dark matter, dark energy and other big mysteries.
To use voids in this way, astronomers must map these regions in detail—a project that is just beginning.
Shown here are voids discovered by the Sloan Digital Sky Survey (SDSS), along with a selection of 16 previously named voids. Scientists expect voids to be evenly distributed throughout space—the lack of voids in some regions on the globe simply reflects SDSS’s sky coverage.”
voids
Sofia Contarini, Alice Pisani, Nico Hamaus, Federico Marulli Lauro Moscardini & Marco Baldi (2023) Cosmological Constraints from the BOSS DR12 Void Size Function Astrophysical Journal 953:46.
Nico Hamaus, Alice Pisani, Jin-Ah Choi, Guilhem Lavaux, Benjamin D. Wandelt & Jochen Weller (2020) Journal of Cosmology and Astroparticle Physics 2020:023.
Sloan Digital Sky Survey Data Release 12
Alan MacRobert (Sky & Telescope), Paulina Rowicka/Martin Krzywinski (revisions & Microscopium)
Hoffleit & Warren Jr. (1991) The Bright Star Catalog, 5th Revised Edition (Preliminary Version).
H0 = 67.4 km/(Mpc·s), Ωm = 0.315, Ωv = 0.685. Planck collaboration Planck 2018 results. VI. Cosmological parameters (2018).
constellation figures
stars
cosmology
Error in predictor variables
It is the mark of an educated mind to rest satisfied with the degree of precision that the nature of the subject admits and not to seek exactness where only an approximation is possible. —Aristotle
In regression, the predictors are (typically) assumed to have known values that are measured without error.
Practically, however, predictors are often measured with error. This has a profound (but predictable) effect on the estimates of relationships among variables – the so-called “error in variables” problem.
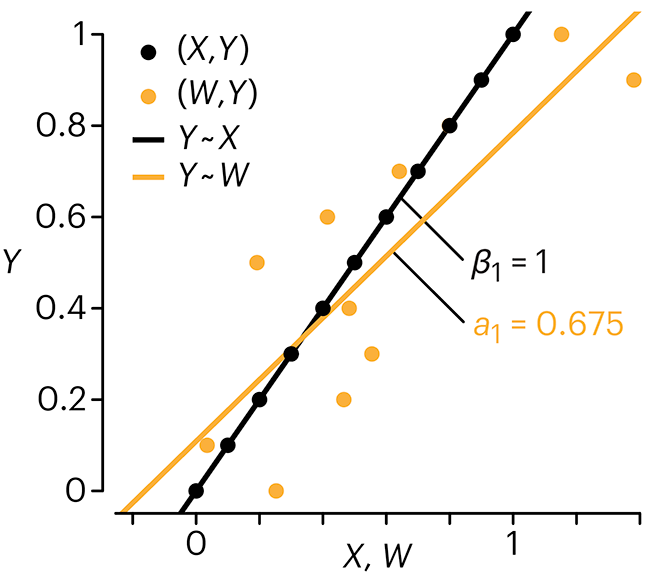
Error in measuring the predictors is often ignored. In this column, we discuss when ignoring this error is harmless and when it can lead to large bias that can leads us to miss important effects.
Altman, N. & Krzywinski, M. (2024) Points of significance: Error in predictor variables. Nat. Methods 20.
Background reading
Altman, N. & Krzywinski, M. (2015) Points of significance: Simple linear regression. Nat. Methods 12:999–1000.
Lever, J., Krzywinski, M. & Altman, N. (2016) Points of significance: Logistic regression. Nat. Methods 13:541–542 (2016).
Das, K., Krzywinski, M. & Altman, N. (2019) Points of significance: Quantile regression. Nat. Methods 16:451–452.