| Requirements |
| Apache https://apache.org mod_perl https://perl.apache.org LWP 5.08 CPAN/modules/by-module/LWP Image::Size 2.6 CPAN/modules/by-module/Image GD 1.8 CPAN/modules/by-module/GD |
How web proxy servers work is one of the darker secrets of the web protocols. In this article we plunge into the depths to show you how to write a proxy module for the Apache web server. This module will handle the proxy's basic job of fetching web documents on your behalf and forwarding them to you, but with a twist: it acts as an advertisement filtering service.
An ordinary web server returns local documents in response to incoming requests. In contrast, a proxying server has elements of both server and client. Instead of sending the proxy server a request for a local document, the client requests the URL of a document located somewhere else on the Internet. The proxy then acts as a client itself by fetching the document and forwarding it to the waiting client.
WHY PROXY?
What's the purpose of this? Proxy servers have several uses. Historically the most important use for proxies was to allow web requests to cross firewalls. Many firewall systems are configured to prohibit port 80 traffic. In order to circumvent this restriction, administrators installed web server proxies on the firewall system. Users then configured their browsers to connect to the firewall machine for web access, and the proxy did the rest. Nowadays all commercial firewall systems come with built-in web proxies and it is no longer necessary to run a general purpose web server on the firewall (which was never much of a good idea for security reasons).
A second reason to proxy is that some proxying servers, Apache included, can cache the contents of the remote documents by sav-ing them to disk files. If they later receive a request for a previously cached document, they return the cached document instead of fetching it remotely. This cuts down on network bandwidth and improves performance, particularly if the server is connected to the Internet by a slow connection. America Online uses caching proxies to improve response time for its large and content-hungry membership. Unfortunately, caching introduces a lot of complexity. When is a cached document no longer fresh, requiring another fetch again from its source? Given the web's eclectic mixture of static pages, CGI scripts, dynamic HTML, and server-side includes, not even the best caching proxies answer this question correctly 100% of the time.
A third use for proxy servers is to filter the request. A proxy server can change the outgoing request or modify the document on its way back to the user. This allows for many useful applications. One popular use of this technique is to create an anonymizing proxy. Such a proxy sits on the Internet somewhere and is used by people who want to protect their identity. As the ano- nymizer receives incoming requests, it strips out all potentially identifying information from the outgoing request, including the User-Agent field, which identifies the browser make and model, HTTP cookies, and the Referer field, which contains the URL of the last document the user viewed.
Like an anonymizer, the example proxy in this article filters the data that passes through it. However, instead of modifying the outgoing request, it modifies the document that is returned to the user. Each proxied document is examined to see whether it might be an advertising banner image. If so, the proxy replaces the banner with a transparent GIF generated on the fly, preserv-ing the size and shape of the original image. The result is shown in Figure 1 ("before") and Figure 2 ("after").
You might use this proxy if you are offended by the web's crass commercialism, or just easily distracted by the blinking, brightly colored ads on your favorite search page. The proxy is written as an add-in module for the Apache server running mod_perl, the embedded Perl interpreter that Doug MacEachern and I wrote about in TPJ #9. The code itself was written by Doug MacEachern, and is used with his permission.
HOW THE PROXY PROTOCOL WORKS
Despite its aura of the arcane, the basic proxy protocol is ridiculously simple. A normal web request begins with the browser sending a server a line of ASCII text that looks like this:
GET /path/to/document HTTP/1.0
The server responds by returning the document located at the indicated path.
In contrast, to make a proxy request, the browser modifies the first line of the request to look like this:
GET https://some.site/path/to/document HTTP/1.0
If the server is proxy-capable, it sees that the requested URL contains the protocol and hostname, and forwards the request to the indicated remote host. Some proxies can only handle requests for HTTP URLs, while others can also handle FTP, Gopher, and (occasionally) WAIS.
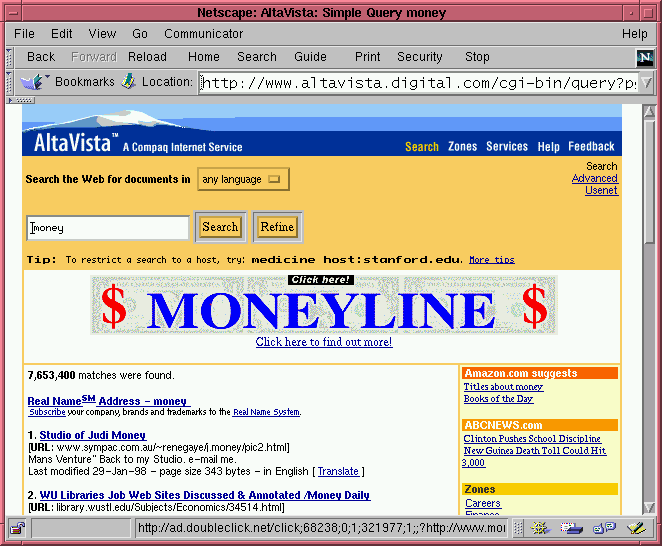
Figure 1: An Alta Vista page with ads
As you may recall from the mod_perl article, Apache divides each browser transaction into ten different phases responsible for handling everything from translating a URI into a physical pathname, to generating the page content, to writing information about the completed transaction into a log file. To extend the server's abilities, you write "handlers" to intercept one or more of the phases, supplementing Apache's built-in handlers or replacing them entirely.
The easiest way to intercept and handle proxy requests is to write two different handlers. The first handler operates during the URI translation phase and is responsible for distinguishing a proxy request from an ordinary one. When the URI translation handler detects a proxy request, it installs the second handler, whose job is to service the content-generation phase of the transaction. It is the content handler that does the actual proxy request and returns the (possibly modified) document.
Listing 1 gives the complete code for a module called Apache::AdBlocker. To use this module, you'll need LWP 5.08 (or higher), Image::Size 2.6 (or higher), and GD 1.18 (or higher). LWP is needed to fetch the remote page, Image::Size is used to determine the size of retrieved GIF and JPEG advertisements, and GD is used to generate a transparent GIF of the same size and shape as the blocked ad. You'll also need Apache 1.3.0 or higher, and a recent version of mod_perl (currently at revision 1.15).
The module starts by declaring its package name. By convention, Apache modules are placed in the Apache:: namespace. We then turns on strict syntax checking, and bring in code from GD, Image::Size and LWP::UserAgent. We also bring in commonly used constants from the Apache::Constants package.
Lines 9 and 10 inherit from the LWP::UserAgent class. LWP::UserAgent is used by the LWP library for all objects that are capable of making web client requests, such as robots and browsers. Although we don't actually override any of LWP::UserAgent's methods, declaring the module as a subclass of LWP::UserAgent allows us to cleanly customize these methods at a later date should we need to. We then define a version number, as every module intended for reusability should.
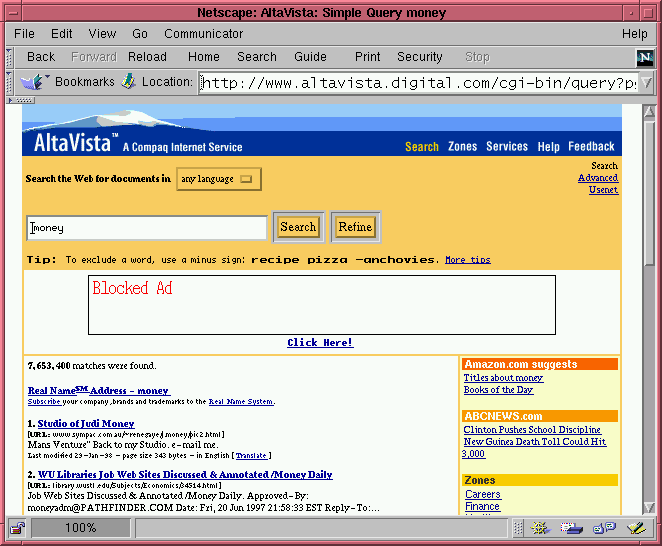
Figure 2: The same page viewed through Apache::AdBlocker.
In lines 11 to 14, we create two package globals. $UA is the LWP::UserAgent that we will use for our proxy requests. It is created using the special token __PACKAGE__, which evaluates at run time to the name of the current package. In this case, __PACKAGE__->new is equivalent to Apache::AdBlocker->new (or new Apache::AdBlocker if you prefer Perl's indirect object style of method call). Immediately afterward we call the object's agent() method with a string composed of the package name and version number. This is the calling card that LWP sends to the remote hosts' web servers as the HTTP User-Agent field. Provided that the remote server records this information, the string that will show up in the access log will be Apache::AdBlocker/ 1.00.
Line 14 defines a regular expression that detects many (but not all) banner ads. It's a simple expression that matches the words "ads", "banners", "promotion" and so on. If you use this service regularly, you'll probably want to broaden this expression to catch more ads.
Lines 16 through 22 define the translation handler, a subroutine which, by convention, is named handler(). This subroutine is simple enough. It begins by copying the Apache request object from the argument stack to a lexical variable, $r. The request object is the interface between user-written modules and Apache, and can be used both to learn about the current transaction and to send commands back to the server.
In this case, we call the request object's proxyreq() method to learn whether the current request is an ordinary one for a local document, or a proxy request for a URL on another system. If this is just an ordinary request, we decline to handle it, returning the DECLINED status code. This tells Apache to handle the translation phase using its default mechanism. Otherwise, we set the stage for a custom content phase handler.
There are now two things that need to be done. First we need to tell Apache that the Perl interpreter will be handling the content phase. We do this with a call to the request object's handler() method, giving it an argument of perlscript, which is the internal name that mod_perl uses for the Perl interpreter. Next we need to tell Perl what user-written subroutine to call when the time comes. We do this with a call to push_handlers(). This routine takes two arguments: the name of the phase to handle, and a reference to the subroutine to call. PerlHandler is the name used for the content phase (the others are more descriptive, such as PerlTransHandler or PerlLogHandler), and proxy_handler() is the subroutine that we want to run. As its name implies, you can call push_handlers() multiple times in order to set up a chain of handlers that will be called in order. (We don't take advantage of this facility in this example.) The last thing we do is to return an OK status code, telling Apache that we handled the request ourselves and no more needs to be done.
Apache now takes over very briefly until it reaches the content-handling phase of the transaction, at which point we find ourselves inside the proxy_handler() routine (lines 24 through 62). As a content handler, this subroutine is responsible for producing the document that is eventually trans-mitted back to the browser. When a proxied document is requested, this routine will be called once for the main document, and once for each image, sound, or other inline content.
The routine starts as before by copying the request object into lexical variable $r. It now uses the LWP library to construct an HTTP::Request, an object that contains the various and sundry headers in an HTTP request. We need all the header fields that were passed to Apache to be passed through to the LWP library. This is so that cookies, authorization information, and the list of acceptable MIME types continue to work as expected. First we create a generic HTTP::Request object by calling its new() method with the request method and the request URI (derived from the request object's method() and uri() methods respectively). Next we copy all the incoming header fields to the new HTTP::Request object. The Apache request object's headers_in() method returns a hash of field name-value pairs. We iterate over this hash, inserting each header into the HTTP::Request object.
If the current request uses the POST method, there's also content data to copy over—typically the contents of fill-out forms. In lines 34 through 39 we retrieve the request's content length by calling the request object's header_in() method with an argument of Content-length. This call is similar to headers_in(), but returns the value of a single field, rather than a hash containing them all (yes, we could reuse %headers_in here, but then you would have missed a useful part ofobject's read() method to read the data into a buffer, and then add the buffer to the outgoing HTTP::Request, with the help of its content() method.
Line 41 is where we actually send out the request. We pass the fully prepared HTTP::Request object to the user agent object's request() method. After a brief delay for the network fetch, the call returns an HTTP::Response object, which we copy into the lexical variable $response. Now the process of copying the headers is reversed. Every header in the LWP HTTP::Response object must be copied to the Apache request object. First we handle a few special cases. The Apache API has a call named content_type() to get and set the document's MIME type. In line 42 we call the HTTP::Response object's header() method to fetch the content type, and immediately pass the result to the Apache request object's content_type() method. Next, we set the numeric HTTP status code and the human-readable HTTP status line (this is the text like 200 OK or 404 Not Found that begins each response from a web server). We call the HTTP::Response object's code() and message() methods to return the numeric code and human readable messages respectively, and copy them to the Apache request object, using the status() and status_line() methods to set the values.
When the special case headers are done, we copy all the other header fields, using the HTTP::Response object's scan() method to rapidly loop through each of the header name-value pairs (lines 47 through 49). For each header field, scan() invokes an anonymous callback routine that sets the appropriate field in the Apache request object with the header_out() method. header_out() works just like header_in(), but accepts the name-value pair of a outgoing header field to set.
At this point, the outgoing header is ready to be sent to the waiting browser. We call the request object's send_http_header() method (line 51) to have Apache send a correctly-formatted HTTP header.
IDENTIFYING ADS
The time has now come to deal with potential banner ads. To identify something an ad, we require that the document be an image and that its URI satisfy a regular expression match that detects words like "advertisement" and "promotion." On line 52 we call the HTTP::Response object's content() method to return the data contained within the response, and store a reference to it in the lexical variable $content. Next, in lines 54-57 we use the information stored in the Apache request object to check whether the MIME type corresponds to an image, and if so, whether the URL matches the ad scanner pattern. If both these conditions are true, we set the content type to image/gif and call an internal subroutine named block_ad() to replace the original image with a custom GIF. On line 59, we send the possibly modified content on to the browser by passing it to the Apache request object's print() method. Lastly, we return a status code of OK to inform Apache that we handled the transaction successfully.
The block_ad() subroutine, beginning on line 64, is short and sweet. Its job is to take an image in any of several possible formats and replace it with a custom GIF of exactly the same dimensions. The GIF will be transparent, allowing the page background color to show through, and will have the words "Blocked Ad" printed in large friendly letters in the upper left-hand corner.
To get the width and height of the image we call imgsize(), a function imported from the Image::Size module. imgsize() recognizes most web image formats, including GIF, JPEG, XBM, and PNG. Using these values, we create a new blank GD::Image object and store it in a variable named $im. We call the image object's colorAllocate() method three times to allocate color table entries for white, black and red, and declare that the white color is transparent, using the transparent() method. The routine calls the string() method to draw the message starting at coordinates (5,5), and finally frames the whole image with a black rectangle. The custom image is now converted into GIF format with the gif() method, and copied into $$data, overwriting whatever was there before.
This ends the module. The only remaining step is to tell Apache about it. You do this by placing the following directive in one of Apache's configuration files:
PerlTransHandler Apache::AdBlocker
Apache::AdBlocker's handler() subroutine will now be invoked to inspect all incoming requests.
If you'd like to try this module out for yourself and your LAN configuration doesn't already require you to use a proxy, you will find the module running at https://www.modperl.com/. Open up your browser's proxy configuration settings, and set HTTP requests to proxy through www.modperl.com using port 80. Now browse the Internet, and see how different things look without all the flashing banner ads! After you're finished be sure to set your browser's proxy settings back to their original values. The modperl server is a lowly 90 MHz Pentium and performance will suffer if too many people decide to use the Ad blocker on a permanent basis.
Lincoln D. Stein wrote CGI.pm.