perl -e '%q=(aa..zz); @k=keys(%q); @v=values(%q); print $k[105],$v[160]
When you see one-liners like the one above, you get the impression that the ASCII character set is deeply ingrained into the heart of Perl. (The one-liner is derived from a posting by Felix Gallo.) However, to the extent that your program can distinguish code from data, it doesn't matter what your computer's underlying character encoding is. In addition to the ubiquitous ASCII (American Standard Code for Information Interchange) and the up-and-coming Unicode, there's an older encoding: EBCDIC, the Extended Binary Coded Decimal Interchange Code. It derives from the first commercial use of computational equipment in the 1890s and is still in use today. In this article, I'll concentrate on the differences between ASCII and EBCDIC in Perl, beginning with a history of how EBCDIC came to be.

History made non-collating
In the late nineteenth century, an enterprising young engineer named Herman Hollerith began an instructorship in mechanical engineering at MIT. In his spare time, he constructed tabulating machines and sorters that outperformed the machines that were being used for the United States census.
Hollerith's tabulating and sorting machines were among the first commercial devices to employ two technical innovations: the use of electricity (though not electronics) and binary internal representations of data. There was, however, no programmatic instruction set so the machines couldn't really be called computers. The tabulators and sorters also used another, much more mature, technology: the punched paper cards that had been used for over a century to "program" weaving looms. Allegedly, the idea for the use of cards (rather than, say, paper tape) occurred to Hollerith while on a train trip during which he noticed the conductor's punching passenger information onto stiff paper cards. Hollerith's tabulation cards had 10 rows and 45 columns of round holes. They measured 3 1/4 by 7 3/8 inches - the size of the dollar bill at the time - so that money-counting machines could be used to process the cards; punch cards haven't changed size since. Hollerith's cards even had the telltale cut corner that helped machine operators align the cards correctly.
Meanwhile, the 1880 census had just taken more than seven years to complete, lasting almost to the beginning of the next census, and so the government held a contest to create a machine that would speed up data gathering and analysis. Hollerith's winning entry was able to count and process the 10,491 citizens of St. Louis in record time, and his equipment was then used to count and profile 62 million people for the 1890 U.S. census. The tabulation required one punch card for each person - a stack that towered higher than the Washington Monument. Yet the tabulation took less than six weeks, and the final 26,408 page report was completed in under three years. Soon Hollerith's tabulators and sorters were used by Russia, Austria, and Canada.
In 1896, Hollerith founded the Tabulating Machine Company, and by 1901 he had added a numeric keypad to help with the input operation of punching cards. In 1911 the company merged with two others to become the Computing Tabulating Recording Company and the machines were employed in the British Census for the first time. The CTR Company became International Business Machines in 1924 (for comparison, Bell Telephone Laboratories was founded in 1925, and the first IBM typewriter was announced in 1935). In 1928 IBM released the Type IV Tabulator, which used cards with 80 columns and 12 rows. Other formats would also compete with these dimensions - the AS/400, still in use today, would eventually support a 96 column card - but it's worth emphasizing the profound impact that 80 by 12 has had on subsequent computer usage: the 80 column by 24 row size of today's "standard" terminal is just enough to edit two Type IV punch cards worth of information.
Standards and code pages
Although the American Standard Association adopted ASCII in 1964, IBM chose to stick with EBCDIC in their System/360 computers, simply because it had been in use in all prior IBM computers and was a legacy of Hollerith's punch cards. ASCII was eventually adopted by the American National Standards Institute (ANSI) and the International Standards Organization (ISO) for some of its character code sets, including ISO-8859-1 (commonly called "quoted-printable"). ASCII is also a subset of the ISO-Latin-1 character set used for hexadecimal encodings on web pages, and it's also a subset of the Unicode two- and three-byte character set designed by Taligent (the collaboration of Apple, Hewlett-Packard, and IBM). Unicode is used by Java, and may soon be integrated into Perl as well. In contrast, EBCDIC is generally considered obsolete, but it's alive and kicking on some computers that run Perl.
Character codes are a necessary part of computing with anything other than pure binary data. If you want to invent a character code of your own, you'll need the upper and lower case 26 letter alphabet, plus the ten digits: 62 characters. Add a dozen or so punctuation characters and one or two dozen control characters (like tab, line feed, carriage return, and form feed), and you can easily generate a list of a hundred characters. ASCII is seven bits, meaning that its indices range from 0 to 27-1, or 0..127, so it has 128 characters. EBCDIC is an eight bit encoding, and so has 256 characters. In ASCII, the mapping from indices to the characters they represent is often counterintuitive; for instance, the digit characters aren't 0..9 but 48..57. (However, the least significant nybble in that sequence is 0..9.) The alphabet forms two sets of consecutive characters in the ASCII: the upper case letters span from 65 to 90 and the lower case letters range from 97 to 122.
In contrast, EBCDIC does not have the alphabet in a stepwise continuous sequence - there are gaps - but both the upper and lower case alphabets are numerically sortable just like ASCII. EBCDIC digits span 240 through 249, so both the last digit and the least significant nybble is 0..9.
Perl on OS/390 OpenEdition
EBCDIC is of special interest to me because I work on an IBM OS/390 computer running OpenEdition, which internally uses EBCDIC.(The OpenEdition environment has been described as Unix on a mainframe; MVS OpenEdition comes with a POSIX shell, an ANSI C/C++ library and compilers, Berkeley style sockets, a hierarchical file system, and a web server. It is POSIX and XPG4.2 compliant and distinct from other interactive environments such as TSO. It supports Perl 5, and it uses the EBCDIC character set.) (In particular, it uses the EBCDIC Latin 1/Open Systems Interconnection Code Page 01047, also known as IBM-1047, but it can display any of several different international variations of EBCDIC.)
We who use Perl on the OS/390 owe a great deal to John Pfuntner (pfuntner@vnet.ibm.com) of IBM, who ported not just Perl 5.000 alpha 12h (in EBCDIC-modified source and binary forms) but a great many other Unix tools available from the "OS/390 OpenEdition Tools and Toys to Download" page, available at: https://www.s390.ibm.com/products/oe/bpxa1toy.html.
After several months of routine use we have only encountered two problems with regular expressions using John Pfuntner's Perl port, and they were easily scripted around. Hence we can run a collection of several hundred scripts and packages with minimal changes. Unless, of course, we want to have a little fun.
Both ASCII (particularly "8-bit" ASCII) and EBCDIC can be "internationalized" so that computers can adopt a variation specific to the local language: ñ for Spanish computers, ö for German computers, and so on. These variations are called locales and the process of converting to them is often called L10N, a curious contraction of the word "localization. " The process of designing software so that L10N is easy is called I18N, for "internationalization." Such matters, particularly as they apply to Japanization (J10N) are nicely addressed in Ken Lunde’s book, Understanding Japanese Information Processing, O’Reilly & Associates, 1993. |
Stupid EBCDIC tricks
The gaps in the EBCDIC alphabets have some startling consequences for the unwary. On an ASCII based computer you can ask Perl 5 to print out the lower case alphabet like so:
perl -e 'for (97..122) {print chr }'
but on an EBCDIC computer it's not quite so elegant:
perl -e 'for (129..137, 145..153, 162..169) {print chr}'
The differences are similar for the upper case alphabet: in ASCII you'd change the list to 65..90, and in EBCDIC you'd need 193..201, 209..217, 226..233. The gaps in EBCDIC are a result of the way the code was laid out to fit on punch cards: groups of 9, 9, and 8 characters separated by 16 or 17 characters. This seems strange, but the regularity of the EBCDIC encoding is more obvious when you use hexadecimal indices to display it:
for ( 0x81..0x89,
0x91..0x99,
0xa1..0xa9,
0xc1..0xc9,
0xd1..0xd9,
0xe1..0xe9,
0xf0..0xf9 ) { print chr }
which prints:
abcdefghijklmnopqr~stuvwxyzABCDEFGHIJKLMNOPQRœSTUVWXYZ0123456789
That's both alphabets, all the digits, and a couple of odd but printable punctuation characters hiding in the middle. A glaring omission from our loop is the 0xb1..0xb9 range, which prints out useful glyphs such as the monetary symbols for the British Pound and the Japanese Yen, as well as some common fractions. By writing the loop with hexadecimal numbers, we illustrate the regularity; the spacings of 9 to 10 characters within each group fit onto the rows of either a 12 by 80 or even the original 10 by 45 Hollerith card. The hexadecimal radix might be an artifact of the way the circuitry was arranged in card tabulators and sorters, machines that didn't treat characters as data types as we do today. Nonetheless, those machines must have been hardwired to treat data of the 0xF\d hexadecimal type as integers subject to the rules of decimal addition.
Fortunately for fans of 2001: A Space Odyssey, the following character transformations steer clear of those strange EBCDIC punch card boundaries (the first comes close, however):
$ perl print pack('c', ord(H)+1); print pack('c', ord(A)+1); print pack('c', ord(L)+1), "\n"; <Ctrl-D> IBM
Another difference between the two encodings is that in ASCII, the upper case alphabet lies below the lower case, whereas in EBCDIC the order and magnitude of the offset is reversed. In ASCII a constant offset of +32 (a bit shift of 5) takes you from an upper case character to its lower case counterpart, whereas on an EBCDIC computer an offset of -64 (opposite bit shift of 6) moves upper case to lower case.
Nevertheless, Perl's uc() function works on EBCDIC:
$ perl -e '$_="the quick brown fox jumped over the lazy dog\n";'\ -e 'print uc($_)' THE QUICK BROWN FOX JUMPED OVER THE LAZY DOG
The ucfirst(), lc(), and lcfirst() functions and the \u, \U, \l, and \L string escapes also work as they do on ASCII computers.
Sorting on EBCDIC is no different than in ASCII:
$ perl -e '@_=qw(THE QUICK BROWN FOX JUMPED OVER THE LAZY DOG);'\ -e 'print sort(@_)' BROWNDOGFOXJUMPEDLAZYOVERQUICKTHETHE
Owing to the cleverness of the OS/390 port, sorting a mixed case string on an EBCDIC computer results in an ASCII-style sort, rather than EBCDIC's pseudo-dictionary order:
$ perl -e ' @a=qw(a b A B);print sort(@a), "\n" ' ABab
However, attempts to create a continuously collated list will simply truncate at the EBCDIC punch card boundaries:
$ perl -e '@a=(a..z); for(@a) {print "$_ ";} print "<\n";' a b c d e f g h i <
This list range truncation is unique to this particular port of EBCDIC Perl and might not occur in future ports.
Interestingly enough, character classes in regular expressions exhibit ASCII-like behavior:
$ perl -e '$_ = "QUICK";' \ -e 'print "string has ", (/[A-Z]/) ? "alpha" : "non-alpha", " chars";' string has alpha chars
Lest you think that merely matched the C, here's another example:
$ perl -e '$_="AIJRSZ"; /([A-Z]+)/; print $1,"\n"' AIJRSZ
It should be noted, however, that a regex range such as [a-z] can match the non-alphabetic gap characters. Here, $s is assigned all the characters in and bounding the first gap in the lower case EBCDIC alphabet:
$ perl -e 'for (137..145) {$s .= chr($_) } $s=~ /([a-z]+)/; print $1,"\n"'
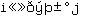
Given the American focus of the ASCII character set (for instance, chr(36) is $, but there are no monetary symbols from other countries) it is amusing to note that IBM-1047 EBCDIC includes the cent symbol (as chr(74)) whereas ASCII does not. When using rlogin to access an OpenEdition session from an ASCII terminal you typically have to use eight bit ASCII extensions to render such symbols.
ASCII to EBCDIC Translators
Thus far I have not mentioned any of the many fine ASCII/EBCDIC translation scripts available from the CPAN, in both the Convert module directory and the scripts/text-processing directory. That's because I haven't needed them, due to the excellent translation utilities already built into OpenEdition.
Conclusion
You can find an apparent ASCIIism in the "Semi-formal Description" of Perl in the second edition of O'Reilly's Programming Perl, where on page 35 it says that "Perl is defined in terms of the ASCII character set." Yet the modified BNF description of the perly.y yacc grammar (Appendix A) defines the CHAR element as [\000-\377]. This goes beyond seven bit ASCII and can be construed as covering the EBCDIC as well.
EBCDIC-based C libraries have been developed that cover all ASCII-style character usages. For the most part the "EBCDIC problem" is just like the Year 2000 Problem: neither is a big deal unless you handle your characters in ways that make certain assumptions about the numeric ranges of the data.
The following one-liner prints the name of our favorite Swiss army chainsaw on EBCDIC computers:
$ perl -e '$e=133;print(chr($e+18),chr($e),chr($e+20),chr($e+14))' perl
Peter Prymmer (pvhp@forte.com) managed to compose most of this article (in pod) using the toyedit.bat editor under Perl/Tk for Windows NT. The output of the Perl one-liners were obtained from an ASCII terminal rlogin session to OS/390 Release 2 OpenEdition. Peter resides in California's Bay area.