What to do about the proliferation of Web junk? Will the Internet actually collapse under its own weight as technology pundit Bob Metcalfe predicted in 1995?
Perl to the rescue. You don't have to wade through nineteen pages of trash to find the gem buried in the twentieth. You can have a Perl agent do the wading for you. In a column that I wrote for WebTechniques in May 1997, I suggested a series of indexes to measure the tastefulness of a Web page. Some of the indexes were serious, such as the ratio of words in hyperlinks to total words on the page (pages with sparsely scattered links are more likely to contain real information than pages consisting almost entirely of links), or the number of potential advertisements on the page. Others were tongue-in-cheek, such as the TutieFrutie Index to measure the number of clashing color changes on the page, or the "Cool! Index" to count the times the words "cool," "neat," or "awesome" appeared. Nevertheless, the intent was sincere: to have a script capable of screening out frivolous or tasteless pages according to whatever your personal criteria happen to be. See page 16 for a listing of the indexes that I proposed.
The agent might be something that you invoke on the spur of the moment ("Hmmm. That URL looks like it might be interesting. Let's have Perl give it the once-over.") A more likely prospect would be to incorporate the agent into a search engine. At the same time the search engine is indexing the keywords on a remote site's pages, it can be calculating and recording the site's tastefulness.
Reactions to the proposal have ranged from the mildly amused to the wildly enthusiastic. It will probably never become part of a commercial product, but at the very least the agent is a good example of how to write a robot with the LWP library.
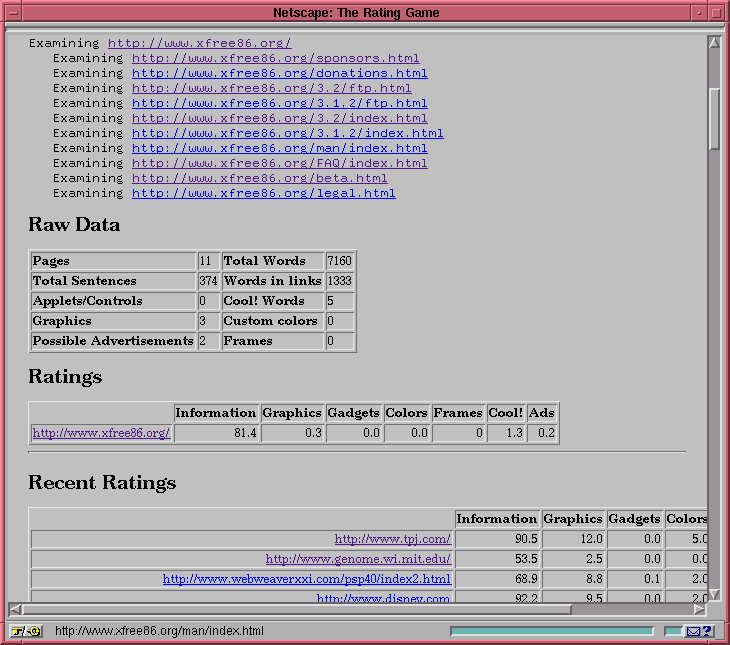
For fun, I implemented the agent as a CGI script. When you first invoke it, it displays a screen prompting the user to type in a URL as shown below. When the user presses the submit button, the script fetches the page, rates it, and displays the results in a table. If the URL contains links to other local pages at the same or lower level in the document tree, the script recurses into them and adds them to the aggregate listing. Since processing lots of pages can take significant time, the script updates the Web page as it goes along, displaying each URL as it is processed. To allow people to see what others have been rating, the page also displays the results from the last thirty URLs fetched; you can see a screenshot on page 13. You can also try out the script yourself at: https://www.genome.wi.mit.edu/~lstein/rater.
I'll spend the rest of this article walking through the script. Although more complex than other example scripts in this series, it's a good example of how to write a Web-walking robot with LWP. It also illustrates a few CGI tricks that haven't popped up in these pages before.
The script has four objectives:
- display the welcome page and prompt for input
- fetch the provided URL and all pages linked from it
- collect statistics on the pages and crunch them into rating indexes
- record recent results into a file that can be displayed at the bottom of the page.
How It Works
Because this script is 400 lines long, I'll intersperse the code with explanations of what's going on. In some places, I depart from the strict linear order of the code in order to make the explanations clearer. If you find this hopelessly confusing, don't despair: you can fetch the entire listing online from the URL given above.
0 #!/usr/bin/perl 1 2 # File: nph-rater.cgi 3 # Copyright 1997, Lincoln D. Stein. All rights reserved. 4 # Permission is granted to use, modify and redistribute 5 # in whole or in part, provided that the above 6 # copyright statement remains prominently displayed. 7 use LWP::UserAgent; 8 use HTML::Parse; 9 use HTTP::Status; 10 use CGI qw/:standard :html3 :nph/; 11 use CGI::Carp; 12
The beginning of the script (lines 7 through 11) loads all the modules we need for the agent. We use the LWP::UserAgent module for fetching URLs, the HTML::Parse module for creating a parse tree of the document's HTML, and the HTTP::Status module for access to various HTTP status code constants. In addition, we load the CGI and CGI::Carp modules. The first provides us with shortcuts for processing CGI variables and writing HTML, while the second makes any error messages generated by the script more informative. A new feature of the CGI library that's not been previously demonstrated in these articles is support for no-parsed header (NPH) scripts, a dialect of CGI in which the script's output is forwarded directly to the browser without extra processing by the Web server. When the symbol :nph is imported from the CGI module, it will automagically generate the HTTP header information necessary to run as an NPH script. In this case, the only reason we want an NPH script is to turn off buffering at the Web server's side of the connection so that we can update the page incrementally. In most cases the server also has to be told that the script is of the NPH variety, usually by tacking the prefix nph- to its name.
13 $MAX_DEPTH=2; # how deeply to recurse 14 15 # words counted towards the cool! index 16 @COOL_WORDS = qw/cool hot groovy neat wild snazzy great awesome wicked/; 17 18 # words that might indicate an advertisement 19 @AD_WORDS = qw/promotion ad advertisement sponsor banner 20 banner commercial promotions ads advertisements 21 banners sponsors commercials doubleclick/; 22 23 # the attributes to count towards tutie-frutie 24 @COLOR_ATTR = qw/color bgcolor text link alink vlink background/; 25 26 # the number of previous rankings to list 27 $PREVIOUS_RANKS = 30; 28 29 # the file containing the previous rankings 30 $RANK_FILE = '/usr/local/etc/www/INDEXER.RANKS';
Lines 13 through 30 contain various user-adjustable globals, including strings to look at when trying to decide if a graphic is an advertisement, and words like "cool" and "snazzy" that might indicate a hyped-up web page. An important constant here is $MAX_DEPTH, which tells the script how deeply to recurse into linked pages. In the code listing here it's set to 2, meaning that only one level of links will be traversed. Higher values make the script investigate a site more thoroughly, at the cost of a longer wait. Also defined here is the name of the file containing the results from previous ratings. You'll need to create this file and make it writable by your Web server before you run this script for the first time.
32 #------------------------------------------------------- 33 # no user serviceable parts below 34 35 # global for collecting statistics 36 %COUNTS = ( 37 'pages' => 0, 38 'mages' => 0, 39 'doodads' => 0, 40 'colors' => 0, 41 'frames' => 0, 42 'ads' => 0, 43 'link_words' => 0, 44 'cool_words' => 0, 45 'total_words' => 0, 46 ); 47 48 grep ($COLOR_ATTR{$_}++, @COLOR_ATTR); 49 $LEVEL = 0; # recursion level 50 $HTML::Parse::IGNORE_UNKNOWN = 0; # don't ignore unknown tags 51 52 $COOL_PATTERN = join("|", @COOL_WORDS); 53 $AD_PATTERN = join("|", @AD_WORDS); 54 $SIG{ALRM} = \&do_alarm; 55 $FH = 'FH0000'; # just a filehandle 56 $|=1; # turn off buffering
Lines 35 through 56 set up various internal globals. We initialize the %COUNTS hash to keep track of Web page statistics. Among the things we record are the number of pages counted, the number of images, the number of applet tags, the number of words in links, and so on. We also create some patterns to find advertisements and hyped-up pages. Several obscure globals are also set here. We zero the variable $LEVEL, which monitors the recursion level, and we set the internal HTML::Parse global $IGNORE_UNKNOWN to false, because by default the parser skips over any HTML tags that it's unfamiliar with, including some of the newer tags that matter to us such as <FRAME>. We also set up a signal handler for alarm() - this becomes important later.
Finally we unbuffer output by setting $| to true, allowing partial pages to be sent to the browser.
58 print header,
59 start_html('The Rating Game'),
60 h1('The Rating Game');
61
62 if (param('action') eq 'explain') {
63 print 'The idea is to automatically collect
information about a linked set of pages ',
64 'that gives the reader some idea of the
flavor of the document. The ratings ',
55 'measure pages\' information content, the
amount of graphics they use, ',
66 'the presence of applets, and the presence
of commercial content.',
67 p(),
68 h2('Key'),
69 dl(
70 dt(strong('Information Index (II)')),
71 dd('Basic measure of the word to link ratio,
defined as:',p(),
72 pre('II = 100 x (1 - (words inside
links / total words in document))'),
73 p()),
74 dt(strong('Graphics Index (GI)')),
75 dd('Measure of the graphics usage of a
page, defined as:',p(),
76 pre('GI = number IMG tags / number pages'),
77 p()),
78 dt(strong('Doodads Index (DI)')),
79 dd('Measure of the number of applets,
controls and scripts, defined as:',p(),
80 pre('DI = number of doodads /
number of pages'),
81 p()),
82 dt(strong('TutieFrutie Index (TFI)')),
83 dd('Measure of how "colorful" a document is,
defined as:',p(),
84 pre('TFI = number of color changes /
number of pages'),
85 p()),
86 dt(strong('Frames Index (FI)')),
87 dd('Measure of the use of frames,
defined as:',p(),
88 pre('FI = number of frame tags'),
89 p()),
90 dt(strong('Cool! Index (C!I)')),
91 dd('Measure of how excited a page is
about itself, defined as:',p(),
92 pre('C!I = 100 x ( exclamation marks +
superlatives ) / total sentences'),
93 p()),
94 dt(strong('Crass Commercialism Index
(CCI)')),
95 dd('Indication of banner advertising on
the page, defined as:',p(),
96 pre('CCI = number of ads /
number of pages'),
97 p(),
98 'This program uses heuristics to count
banner advertisements and may ',
99 'not always guess correctly.'
100 )
101 );
102 } else {
103 print
104 'This CGI script was written to go along with my
May 1997',
105 a({-href=>'https://www.webtechniques.com/'},
'WebTechniques'),' column ',
106 cite('Sifting the Wheat from the Chaff'),'. It
demonstrates a way of ',
107 'rating Web pages automatically for information
content. To use it, enter a full ',
108 'URL in the text field below and press',
strong('Rate'),
109 '. After some processing, the ',
110 'script will report a variety of rating indexes.',
111 p(),
112 'This script isn\'t fast, so be patient. In order
to minimize system load, ',
113 'the script currently only descends one level
of links.',
114 p(),
115 a({-href=>script_name() . '?action=explain',
-target=>'explanation'},'Explain the ratings.');
Lines 58 through 115 prints out the welcome page and instructions for the user. This part of the script makes extensive use of the HTML shortcuts provided by the CGI module; see my previous TPJ articles for details. If you don't know what's going on, suffice it to say that h1() produces a level 1 header, a() produces a link, and so on. The script actually includes its own documentation; if called with the CGI parameter named action set to explain (i.e. cgi-bin/nph-rater.cgi?action=explain) it displays text explaining the rating system. Otherwise it prints the normal welcome page. The check for this parameter is in line 62. An interesting trick related to this can be found on line 115, where you'll find this bit of code used to generate the self-referencing URL that summons up the explanatory text:
a({-href => script_name(). '?action=explain',
-target => 'explanation'},
'Explain the ratings.');
This generates a link with the TARGET attribute set. On frames-aware browsers (primarily Netscape and Internet Explorer), this causes the explanatory text to be displayed in a newly-created browser window.
117 print_prompt(); 118 %stats = process_url($URL) if $URL = param('url_to_process'); 119 print_previous(%stats); 120 } 121 122 print_tail(); 123 124 exit 0; 125 126 sub print_prompt { 127 print hr, 128 start_form, 129 'URL to Rate:', br, 130 textfield(-name=>'url_to_process',-size=>60),br, 131 submit('Rate'), 132 end_form; 133 } ... 146 sub print_tail { 147 print hr(), 148 address(a({-href=>'/~lstein'},"Lincoln D. Stein"),br, 149 a({-href=>'https://www.genome.wi.mit.edu/'},'Whitehead Institute/MIT Center for Genome Research')); 150 }
Line 117 invokes the print_prompt() subroutine (lines 126-133), which uses standard CGI module calls to create a small fill-out form. Aside from the submit button, only one form element is defined: a text field named url_to_process. After the form is submitted, a like-named CGI parameter will contain the URL to process. Line 118 checks this parameter, and if present passes its value to the aptly-named process_url() function for processing and display. The previous thirty statistics are next fetched from a disk file and printed at the bottom of the page. Finally, the script prints out the bottom of the HTML page (subroutine print_tail(), lines 146-150) and exits.
135 sub process_url {
136 my $url = shift;
137 print hr(),
138 h2('Progress');
139 print "<PRE>\n";
140 collect_stats(new URI::URL $url);
141 print "</PRE>\n";
142
143 return summary_statistics($url) if $COUNTS{'pages'};
144 }
The clever LWP agent begins with the call to process_url() (lines 135-144). Because the script may take some time to traverse the linked pages, we're careful to keep the user on top of what's going on. We print out a level 2 header labeled "Progress" and then start a preformatted section with the <PRE> HTML tag. In line 140 we call the LWP library to create a new URI::URL object, and pass this object to the subroutine collect_stats(). As collect_stats() traverses the document tree, it prints out an indented set of URLs, which are immediately displayed. As collect_stats() works, it adds the collected statistics to the global variable %COUNTS. When it's finished, we call the routine summary_statistics() to crunch the numbers and format them.
245 sub collect_stats {
246 local $CURRENT_DOC = shift;
247 return undef unless $LEVEL < $MAX_DEPTH;
248
249 my $path = $CURRENT_DOC->abs->path;
250 return undef if $BEEN_THERE{$path}++;
251
252 my $href = $CURRENT_DOC->abs->as_string;
253
254 print ' 'x($LEVEL*3),"Examining ",
a({-href=>$href},$href)," ";
255
256 $LEVEL++;
257 my $agent = new LWP::UserAgent;
258 my $request = new HTTP::Request('GET',$CURRENT_DOC);
259 my $response = $agent->request($request);
260
261 local ($BASE,$INSIDE_A_LINK,$TEXT);
262
263 TRY:
264 {
265 # replace with a more informative error message later
266 do { print em("unable to fetch document\n");
last TRY } unless $response->is_success;
267
268 # This guarantees that we get the correct base docu-
269 # ment even if there was a redirect thrown in there.
270 if ($response->request->url->abs->path ne $path) {
271 $CURRENT_DOC = $response->request->url;
272 last TRY if $BEEN_THERE{$CURRENT_DOC->abs->path}++;
273 }
274
275
276 # make sure that it's an HTML document!
277 my $type = $response->header('Content-type');
278 do { print em("not an HTML file\n"); last TRY; }
unless $type eq 'text/html';
279
280 my $parse_tree = parse($response->content);
281 do { print em("unable to parse HTML\n"); last TRY; }
unless $parse_tree;
282
283 print "\n";
284
285 $COUNTS{'pages'}++;
286 $parse_tree->traverse(\&process_page);
287
288 # for non-obvious reasons, we have to collect all
289 # the text before we can count the sentences.
290 $COUNTS{'sentences'} += sentences($TEXT);
291
292 $parse_tree->delete;
293 }
294 $LEVEL--;
295 return 1;
296 }
Lines 245 through 296 contain the code for collect_stats(), the subroutine responsible for fetching the document at the indicated URL and its linked pages. We begin by loading the URI::URL object previously created in the call to process_url() into a dynamically-scoped variable named $CURRENT_DOC. Although lexically-scoped variables created with my are usually preferable, dynamic scoping with local comes in handy when you want to create a set of variables that can be shared among a series of recursive subroutines. We use the same trick on line 261, where the values of pseudo-globals $BASE, $INSIDE_A_LINK and $TEXT are defined.
Next we perform a check for the depth of recursion. We return immediately if the global variable $LEVEL reaches $MAX_DEPTH (line 247). Following this is another important check: If we've seen this URL before, we must also return without processing the page. Because tasteless Web pages often contain a series of tangled self-referential links, we have to be careful not to count the same page twice. This is done by calling the URL object's abs() and path() methods. Together these methods resolve relative URLs into absolute ones (taking the BASE tag, if any, into account), strip off the protocol, host name, query string and "#" parts of the URL, and return the naked URL path. We compare this path to %BEEN_THERE, a hash of visited URLs, and exit if we've seen it already.
On lines 252 through 254, we convert the URL object into a string by calling the URL's as_string() method, and print it out, tabbing over an appropriate number of spaces according to the recursion level. When this is done, we bump up the $LEVEL global.
The section between lines 257-259 creates a new LWP UserAgent and attempts to fetch the document at the current URL. The HTTP response from the attempt (whether successful or unsuccessful) is stored in the variable $response. We now attempt to process the response (lines 263-296). First we check the HTTP result code by calling the response's is_success() method. If unsuccessful, we print an error message and bail out. Next, we fetch the actual URL associated with the response and update the $CURRENT_DOC variable if it is different from what we attempted to fetch. Usually an HTTP request returns the same URL that we attempted to fetch, but redirections muddy the waters. Again, we need to check that we aren't counting the same document twice. The final sanity check is for the returned document's MIME type (lines 277 and 278). If it's an HTML file we proceed; otherwise we exit the subroutine.
Now that we have an HTML document in hand, we parse it (line 280) by passing it to parse(). If successful, this returns an HTML::Parse object containing a tree of the document's HTML. We bump up the page count (line 285) and scrutinize the document by calling the traverse() method.
378 sub parse {
379 my $content = shift;
380 return eval <<'END';
381 alarm(10);
382 my $f=parse_html($content);
383 alarm(0);
384 $f;
385 END
386 }
The parse() subroutine (lines 378 through 386) is worth a quick look. A problem with the LWP HTML parsing routines is that bad HTML (which, sadly, is far from uncommon!) causes the parse routines to hang indefinitely. For this reason, we wrap LWP's parse_html() function in an eval() statement containing an alarm. If LWP hasn't finished parsing the document after ten seconds has elapsed, we print a warning message and return an undefined value.
298 sub process_page {
299 my ($node,$start,$depth) = @_;
300 if (ref($node)) { # we have subparts
301
302 $BASE = $node->attr('href')
303 if $node->tag eq 'base';
304
305 $COUNTS{'images'}++ if $start &&
$node->tag eq 'img';
306 $COUNTS{'doodads'}++ if $start &&
$node->tag =~ /^(applet|object|script)/; 307 #
308 # count the number of color changes
309 grep($COLOR_ATTR{$_} && $COUNTS{'colors'}+
keys %{$node}) if $start;
310
311 $COUNTS{'frames'}++ if $start &&
$node->tag eq 'frame';
312 $COUNTS{'ads'}++ if $start && $node->tag eq
'img'&& is_ad($node->attr('src'));
313
314 # here's where we handle links and recursion
315 if ($node->tag eq 'a') {
316 my $href = $node->attr('href');
317 if ($href) {
318 if (is_child_url($href)) {
319 my $newdoc = new URI::URL($href,$BASE ||
$CURRENT_DOC->abs); 320 collect_stats($newdoc) unless
$start;
321 }
322 $INSIDE_A_LINK = $start;
323 }
324 }
325
326 # step into frames correctly
327 if ( $start && ($node->tag eq 'frame') ){
328 my $href = $node->attr('src');
329 if ($href && is_child_url($href)) {
330 my $newdoc = new URI::URL($href,$BASE || $CURRENT_DOC->abs);
331 collect_stats($newdoc);
332 }
333 }
334
335 } else { # if we get here we've got plain text
336 my @words = $node =~ /(\S+)/g;
337 $COUNTS{'link_words'} += @words if $INSIDE_A_LINK; 338
$COUNTS{'total_words'} += @words;
339 $COUNTS{'cool_words'} += is_cool($node);
340 $TEXT .= $node . " ";
341 }
342
343 return 1;
344 }
345
346 sub is_cool {
347 my $text = shift;
348 my ($exclamation_marks) = $text=~tr/!/!/;
349 my (@cool_words) = $text=~/\b($COOL_PATTERN)\b/oig;
350 return $exclamation_marks + @cool_words;
351 }
352
353 sub sentences {
354 my $text = shift;
355 # count capital letters followed by some non-
356 # punctuation, followed by punctuation and a space.
357 my (@sentences) = $text=~/([A-Z].+?[.!?]\s)/gm;
358 return scalar(@sentences);
359 }
360
361 sub is_ad {
362 my $url = shift;
363 return undef unless $url;
364 return $url=~/\b($AD_PATTERN)\b/oi;
365 }
366
367 sub is_child_url {
368 my $url = shift;
369 return undef if $url =~ /^\w+:/;
370 return undef if $url =~ m!^/!;
371 return undef if $url =~ /^\.\./;
372 1;
373 }
The statistics-gathering takes place in the subroutine named process_page() (lines 298-344). process() is called recursively by the HTML object's traverse() method. Each time it's invoked, process() is passed three parameters: a node corresponding to the current HTML element, a flag indicating whether the element is an opening tag or a closing tag, and the depth of the element in the parse tree. The subroutine's main task is to collect statistics about the page. First we check whether the node is a reference to an HTML object, which occurs when we're inside a tag of some sort. If we are, we can extract the tag's name by calling the object's tag() method and the values of any attributes with its attr() method. In most cases the statistics we gather are pretty simple. For example, if we see an <IMG> tag (line 305), we bump up the 'images' field in the %COUNTS global. Similarly we bump the 'doodads' field if we find an <APPLET>, <OBJECT> or <SCRIPT> tag. Detecting potential advertisements is a little more difficult. We look for an <IMG> tag whose SRC URL contains one or more of the words "promotion," "ad," "advertisement," "sponsor," "banner," or "commercial." Empirically, the majority of banner ads contain one of these telltale strings. We also specifically check for URLs from the ubiquitous DoubleClick advertising agency.
The <BASE> Tag
A few tags are special. If we encounter a <BASE> tag, we extract its HREF attribute and store it in the packagewide variable $BASE. This allows us to properly resolve relative URLs detected anywhere in the document. If we find a hyperlink anchor (lines 315 to 324), we extract its HREF attribute and check whether it is a relative reference to a document on the same or lower level as the current one. If it satisfies this test, we create a new URL object (line 319), being careful to resolve the relative reference with $BASE if defined, or the URL of the current document if not. We then recursively pass the resolved URL object to collect_stats(), processing the linked document in a depth-first manner.
On line 322, we set the $INSIDE_A_LINK dynamically-scoped global to true when we encounter the opening tag of a link, and false when the corresponding closing tag is encountered. This flag allows us to identify words that are inside links for the purposes of creating the Information Index.
Lines 326 to 333 contain code for handling frames correctly. The code here is almost identical to that used for handling links.
Lines 335 to 341 are executed when the parse tree traverses the plain text part of the HTML page. This section tallies various word counts, keeping track of total words, words inside links, and words of the "cool" persuasion. We also need to tally the number of sentences on the page. Since the HTML parser, by its nature, breaks sentences into chunks and presents them to process() in discontinuous pieces, we simply concatenate the sentence fragments into the dynamically-scoped variable $TEXT, and defer tallying sentences until the entire HTML tree traversal is finished (line 290).
152 sub summary_statistics {
153 my $href = shift;
154 print h2('Raw Data'),
155 table({-border=>''},
156 TR({-align=>LEFT},
157 th('Pages'), td($COUNTS{'pages'}),
158 th('Total Words'), td($COUNTS{'total_words'})),
159 TR({-align=>LEFT},
160 th('Total Sentences'),td($COUNTS{'sentences'}),
161 th('Words in links'),td($COUNTS{'link_words'})),
162 TR({-align=>LEFT},
163 th('Applets/Controls'), td($COUNTS{'doodads'}),
164 th('Cool! Words'), td($COUNTS{'cool_words'})),
165 TR({-align=>LEFT},
166 th('Graphics'), td($COUNTS{'images'}),
167 th('Custom colors'), td($COUNTS{'colors'})),
168 TR({-align=>LEFT},
169 th('Possible Advertisements'), td($COUNTS{ads}),
170 th('Frames'), td($COUNTS{'frames'}))
171 );
172 my %i = (compute_indices(%COUNTS),'href'=>$href);
173 print h2('Ratings'),summary_table(\%i);
174 return %i;
175 }
176
177 sub summary_table {
178 my (@row) = @_;
179 my (@rows,$i);
180 foreach $i (@row) {
181 push(@rows,
182 td([a({-href=>$i->{href}},$i->{href}),
183 sprintf("%2.1f",$i->{II}),
184 sprintf("%2.1f",$i->{GI}),
185 sprintf("%2.1f",$i->{DI}),
186 sprintf("%2.1f",$i->{TFI}),
187 $i->{FI},
188 sprintf("%2.1f",$i->{'C!I'}),
189 sprintf("%2.1f",$i->{CCI})]
190 )
191 );
192 }
193 return join("\n",
194 table( {-border=>''},
195 TR(th(),
196 th('Information'),
197 th('Graphics'),
198 th('Doodads'),
199 th('Colors'),
200 th('Frames'),
201 th('Cool!'),
202 th('Ads')),
203 TR({-align=>RIGHT},\@rows)
204 )
205 );
206 }
...
231 sub compute_indices {
232 my (%COUNTS) = @_;
233 my %indices = (
234 II => 100 * (1 - $COUNTS{'link_words'}/
($COUNTS{'total_words'} || 1)),
235 GI => $COUNTS{'images'}/$COUNTS{'pages'},
236 DI => $COUNTS{'doodads'}/$COUNTS{'pages'},
237 TFI => $COUNTS{'colors'}/$COUNTS{'pages'},
238 FI => $COUNTS{'frames'},
239 'C!I'=> 100 * ($COUNTS{'cool_words'}/
($COUNTS{'sentences'} || 1)),
240 CCI => $COUNTS{'ads'}/$COUNTS{'pages'},
241 );
242 return %indices;
243 }
When collect_stats() has finished processing all the linked documents, %COUNTS contains the final tallies. The subroutine summary_statistics() (lines 152 through 175) creates an HTML table showing the raw statistics, and invokes compute_indices() (lines 231-243) to crunch these numbers according to the rating scheme. The crunched results are passed on to summary_table() (lines 177-206) to format the results into a nice HTML table.
208 sub print_previous {
209 my (%current) = @_;
210 my $fh = open_and_lock($RANK_FILE);
211 my (@previous_ranks);
212 chomp(@previous_ranks = <$fh>);
213 if (@previous_ranks) {
214 my (@processed) = map { {split("\t")} }
@previous_ranks;
215 print hr(), h2('Recent Ratings'),
summary_table(@processed);
216 }
217
218 unless ($COUNTS{'pages'}) {
219 unlock($fh);
220 return;
221 }
222
223 unshift(@previous_ranks, join("\t", %current));
224 pop(@previous_ranks)
if @previous_ranks > $PREVIOUS_RANKS;
225 seek($fh,0,0);
226 print $fh join("\n", @previous_ranks), "\n";
227 truncate($fh,tell($fh));
228 unlock($fh);
229 }
The script's last task is to add the current site's rating results to a list of the last thirty ratings. We do this in a fairly crude manner in the subroutine print_previous(), which you'll find in lines 208 through 229. We keep the results as a simple text file, one line per rating. Using Perl's flock() call, we gain exclusive read/write access to the text file. This is necessary to avoid multiple instances of the CGI script from trying to update the file simultaneously.
392 # ------------------- file locking code ------------ 393 # This bit of code creates an advisory lock on the 394 # indicated file and returns a file handle to it. 395 sub LOCK_SH { 1 } 396 sub LOCK_EX { 2 } 397 sub LOCK_NB { 4 } 398 sub LOCK_UN { 8 } 399 400 sub open_and_lock { 401 my $path = shift; 402 my $fh; 403 404 local($msg)=''; 405 local $oldsig = $SIG{'ALRM'}; 406 $SIG{'ALRM'} = sub { $msg='timed out'; $SIG{ALRM}=$oldsig; }; 407 alarm(5); 408 409 $fh = ++$FH; 410 open ($fh,"+<$path") or die("Couldn't open $path: $!"); 411 412 # now try to lock it 413 die("Couldn't get write lock (" . ($msg || "$!") . ")") 414 unless flock ($fh,LOCK_EX); 415 416 $fh; 417 } 418 419 sub unlock { 420 my $fh = shift; 421 flock($fh,LOCK_UN); 422 close $fh; 423 }
Lines 392-423 contain the boilerplate code that I use for this type of file locking. If we successfully obtain a lock, we read the entire contents of the file into list, and format it into an HTML table by calling summary_table() once more to do the dirty work. When this is done, we throw out the first entry in the list and add the current document's ratings to the end of the list. We then format the numbers into a table and write the results back to the file. Finally we unlock the file and return.
For Extra Credit
The demonstration script on my Web site is slightly more sophisticated than what I've shown here. It turns out that many high-end Web sites customize their content for their user's browser. Browsers that identify themselves as Netscape or Netscape compatible get snazzy graphics, frames, and applets. Other browsers get a toned down page. With a little extra programming effort, the rater script can pretend to be various popular brands of browser. Try rating the same pages while impersonating different browsers and see what happens!
Lincoln Stein wrote CGI.pm.