home > results > Nixon vs. Kennedy (combined)
Word Analysis of 1960 U.S. Presidential Debates
Richard Nixon vs. John F. Kennedy (combined debates)
26 September — 21 October 1960
Introduction
Speaking Turns and Interruptions
Here, I look at the length of each turn of uninterrupted speech.
Table 1
length of sections in words
The number of uninterrupted deliveries (sections), mode/median/mean length of sections in words, and the shortest section length in words that composed 10%, 50% and 90% of the debate.
Flesch-Kincaid Reading Ease and Grade Level
The Flesch-Kincaid reading ease and grade level metrics are designed to indicate how difficult a passage in English is to understand.
Reading ease ranges from 100 (easiest) down to 0 (hardest) and can be interpreted as follows
| Very easy to read. Easily understood by an average 11-year-old student. |
| Easy to read. Conversational English for consumers. |
| Fairly easy to read. |
| Plain English. Easily understood by 13- to 15-year-old students. |
| Fairly difficult to read. |
| Difficult to read. |
| Very difficult to read. Best understood by college/university graduates. |
| Extremely difficult to read. Best understood by college/university graduates. |
The grade level corresponds roughly to a U.S. grade level. It has a minimum value of –3.4 and no upper bound.
Two sets of readability scores are calculated. One for the entire debate and one that only considers section with at least 9 words.
Table 2a
readability — entire debate
Flesch-Kincaid reading ease and grade level.
Table 2b
readability — excluding short sections
Flesch-Kincaid reading ease and grade level for sections with at least 9 words.
Sentence Size
Table 3
sentence size
Number of sentences spoken by each speaker and sentence word count statistics. Number of words in a sentence is shown by average and 50%/90% cumulative values for all, stop and non-stop words.
Word Statistics
Debate Word Count
Summary Word Count
The summary word count reports the total number of words and the
number of unique, non-stop words
used by each candidate. Word number is expressed as both absolute and
relative values.
Table 4a
all words
Number of all words and unique words used by each speaker.
Table 4b
exclusive and shared words
Words exclusive to speaker (e.g. speaker A
but not speaker B) and shared by speakers (speaker A
and B).
Stop Word Contribution
In the table below, the candidates' delivery is partitioned into stop and non-stop words. Stop words (full list) are frequently-used bridging words (e.g. pronouns and conjunctions) whose meaning depends entirely on context. The fraction of words that are stop words is one measure of the complexity of speech.
Table 5a
non-stop words
Counts of stop and non-stop words.
Table 5b
exclusive and shared non-stop words
Non-stop words exclusive to speaker (e.g. speaker A
but not speaker B) and shared by speakers (speaker A
and B).
Word frequency
The word frequency table summarizes the frequency with which words
were used. I show the average word frequency and the weighted
cumulative frequencies at 50 and 90 percentile. The average word
frequency indicates how many times, on average, a word is used. For a
given fraction of the entire delivery, the weighted cumulative
frequency indicates the largest word frequency within this fraction
(details about weighted
cumulative distribution).
Table 6a
word use frequency
Average and 50%/90% percentile word frequencies.
Table 6b
exclusive and shared non-stop word use frequency
Average and 50%/90% cumulative percentile word frequencies. Non-stop words exclusive to speaker (e.g. speaker A
but not speaker B) and shared by speakers (speaker A
and B).
All further word use statistics represent content that has been filtered for stop words, unless explicitly indicated.
Part of Speech Analysis
In this section, word frequency is broken down by their part of
speech (POS). The four POS groups examined are nouns, verbs,
adjectives and adverbs. Conjunctions and prepositions are not
considered. The first category (n+v+adj+adv) is composed of all four
POS groups.
Part of Speech Count
Table 7
part of speech count
Count of words categorized by part of speech (POS).
Part of Speech Frequency
Table 8
part of speech frequency
Frequency of words categorized by part of speech (POS).
Part of Speech Pairing
Through word pairing, I extract concepts from the text. The number of unique word pairs is a function of sentence length and is one of the measures of complexity.
Table 9a
part of speech pairing — Richard Nixon
Word pairs (total and unique) categorized by part of speech (POS)
Table 9b
part of speech pairing — John F Kennedy
Word pairs (total and unique) categorized by part of speech (POS)
Table 9c
unique part of speech pairing — candidate comparison
Unique word pairs categorized by part of speech (POS)
You can really get into the weeds here. Parts of speech are counted more granularly in these tables — nouns and verbs are split into classes and many other word types are shown, such as conjunctions and prepositions.
Table 10a
detailed POS tags — nouns and verbs
Count by part of speech tag:
NN (noun, singular),
NNP (proper noun, singular),
NNPS (proper noun, plural),
NNS (noun plural),
VB (verb, base form),
VBD (verb, past tense),
VBG (verb, gerund/present participle),
VBN (verb, past participle),
VBP (verb, sing. present, non-3d),
VBZ (verb, 3rd person sing. present)
Table 10b
detailed POS tags — adjectives, pronouns, adverbs and wh-words
Count by part of speech tag:
JJ (adjective),
JJR (adjective, comparative),
JJS (adjective, superlative),
PRP (personal pronoun),
PRP$ (possessive pronoun),
RB (adverb),
RBR (adverb, comparative),
RBS (adverb, superlative),
WDT (wh-determiner),
WP (wh-pronoun),
WP$ (possessive wh-pronoun),
WRB (wh-abverb)
Table 10c
detailed POS tags — prepositions, conjunctions, determiners and others
Count by part of speech tag:
CC (coordinating conjunction),
CD (cardinal digit),
DT (determiner),
EX (existential there),
FW (foreign word),
IN (preposition/subordinating conjunction),
MD (modal),
PDT (predeterminer),
POS (possessive ending),
RP (particle),
TO (to),
UH (interjection)
Exclusive and Shared Usage
This section enumerates words that were exclusive to a
candidate (e.g. used by one candidate but not the other). This content
provides insight into what the candidates' priorities are and
reveals differences in perspective on similar topics.
For a given part of speech, the table breaks down the number of
words that were spoken by only one of the candidates or both
candidates (intersection). The last row includes words spoken by
either candidate (union).
Table 11
exclusive word usage
Total and unique words used exclusively by a candidate, or by both.
Pronoun Usage
This section explores pronoun use in detail. Refer to the methods section for details.
Pronoun Count
Fraction of all words that were pronouns.
Table 12a
pronoun fraction
Fraction of words that were pronouns.
Table 12b
exclusive and shared pronouns
Pronouns exclusive to speaker (e.g. speaker A
but not speaker B) and shared by speakers (speaker A
and B).
Pronoun by Person, Gender and Count
Pronoun usage by person (1st, 2nd, 3rd), gender (masculine, feminine, neuter) and count (singular, plural).
Table 13a
Pronoun by person
Count of pronouns by first, second or third person.
Table 13b
Pronoun by gender
Count of pronouns by masculine, feminine or neuter gender.
Table 13c
Pronoun by number
Count of pronouns by singular or plural.
First and third person pronouns — a closer look
These tables break pronouns by interesting contrasts. For example, the ratio of singular to plural 1st person pronouns reveals the use of "I/my/myself" vs. "we/our/ours".
Table 14a
1st person pronouns, by count
Count of singular and plural first person pronouns. This table contrasts use of I/my/myself vs. we/our/ours.
Table 14b
3rd person pronouns, by count
Count of singular and plural third person pronouns. This table contrasts he/she/his/her/it vs. they/them/theirs.
Table 14c
Me and you — 1st person singular and second person pronouns
Count of 1st person singular and second person pronouns. This table contrasts me/my/myself vs you/yours/yourself.
Table 14d
I, me, myself and my — closer look at 1st person singular pronouns
Count of specific 1st person singular pronouns: I, me, myself and my.
Pronouns by Category
This table tallies the use of pronoun by category. The categories are personal, demonstrative, indefinite, object, possessive, interrogative, others, relative, reflexive. Note that some pronouns that belong to multiple categories are counted in only one. For a list of pronouns for each category, see the pronoun methods section.
Table 15
Pronouns by cateogry
Count of pronouns by category.
Noun Phrase Usage
Noun phrases were extracted from the text and analyzed for
frequency, word count, unique word count and richness. Single-word phrases were not counted.
Top-level noun phrases are those without a parent noun phrase (a
parent phrase is one that a similar, longer phrase). Derived noun
phrases are those with a parent (more
details about noun phrase analysis).
The top-level noun phrases can be interpreted as independent
concepts. Derived noun phrases can be interpreted as variants on
concepts embodied by the top-level phrases.
Noun Phrase Count and length
This table reports the absolute number of noun phrases, which is
related to the number of nouns, and their length.
Table 16a
noun phrase count
Counts of noun phrases in words and per noun.
Table 16b
noun phrase length
Average and 50%/90% cumulative length of noun phrases, in words.
Exclusive and Shared Noun Phrase Count and length
Table 17a
exclusive and shared noun phrase count
Counts of exclusive and shared noun phrases in words and per noun.
Table 17b
exclusive and shared noun phrase length
Average and 50%/90% cumulative length of noun phrases, in words.
Windbag Index
The Windbag Index is a compound measure that characterizes the complexity of speech. A low index is indicative of succinct speech with low degree of repetition and large number of independent concepts.
Because the index uses the ratio of unique words to all words, it will be larger for longer debates because the fraction of unique words shrinks. Therefore, Windbag Index across debates can only be compared if the number of words is similar.
Table 18
windbag index
Windbag Index for each speaker. The higher the value, the more repetitive the speech.
Word Clouds
In the word clouds below, the size of the word is proportional to
the number of times it was used by a candidate (method details).
Not all words from a group used to draw the cloud fit in the image
— less frequently used words for large word groups may fall
outside the image.
All Words for Each Candidate
Each candidate's debate portion was extracted and frequencies were
compiled for each part of speech (noun, verb, adjective, adverb), with
words colored by their part of speech category.
The distribution of sizes within a tag cloud follows the frequency
distribution of words. However, word size cannot be compared between
clouds, since the minimum and maximum size of the words is fixed.
Debate Word Cloud for Richard Nixon - all words

Size proportional to word frequency. Color encodes part of speech: noun verb adjective adverb
Debate Word Cloud for John F Kennedy - all words

Size proportional to word frequency. Color encodes part of speech: noun verb adjective adverb
Exclusive Words for Each Candidate
The clouds below show words used exlusively by a candidate. For
example, if candidate A used the word "invest" (any number of times),
but candidate B did not, then the word will appear in the exclusive word
tag cloud for candidate A.
Words exclusive to Richard Nixon

Size proportional to word frequency. Color encodes part of speech: noun verb adjective adverb
Words exclusive to John F Kennedy

Size proportional to word frequency. Color encodes part of speech: noun verb adjective adverb
Pronouns for Each Candidate
Word clouds based on only pronouns.
Pronouns for Richard Nixon

Size proportional to word frequency. Color encodes pronoun type: masculine feminine neuter 1st person 2nd person singular plural other
Pronouns for John F Kennedy

Size proportional to word frequency. Color encodes pronoun type: masculine feminine neuter 1st person 2nd person singular plural other
Part of Speech Word Clouds
In these clouds, words from each major part of speech were colored
based on whether they were exclusive to a candidate or shared by the
candidates.
The size of the word is relative to the frequency for the candidate
— word sizes between candidates should not be used to indicate
difference in absolute frequency.
Cloud of noun words, by speaker
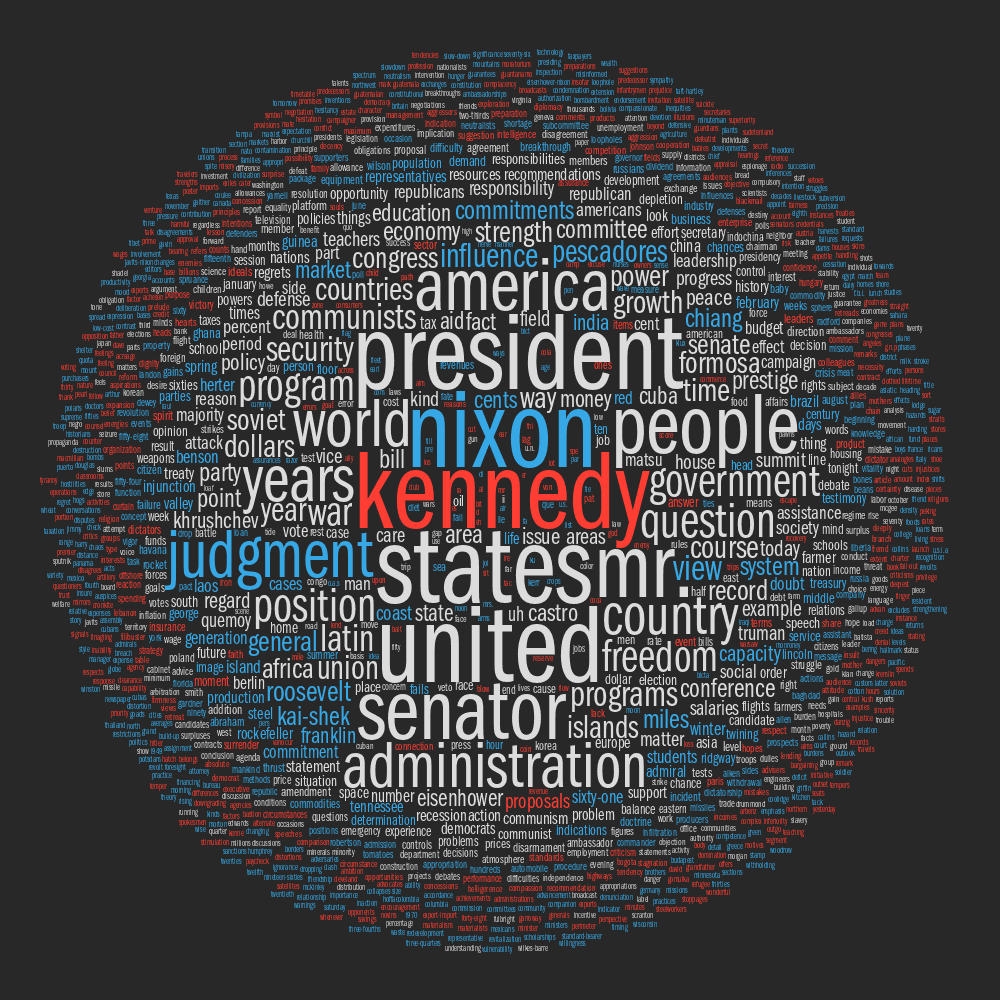
Words unique to each candidate (Nixon, Kennedy) and those spoken by both.
Cloud of verb words, by speaker

Words unique to each candidate (Nixon, Kennedy) and those spoken by both.
Cloud of adjective words, by speaker

Words unique to each candidate (Nixon, Kennedy) and those spoken by both.
Cloud of adverb words, by speaker

Words unique to each candidate (Nixon, Kennedy) and those spoken by both.
Cloud of all words, by speaker

Words unique to each candidate (Nixon, Kennedy) and those spoken by both.
Word Pair Clouds for Each Candidate
Pairs used only once during the debate are not shown.
word pairs for Richard Nixon

▲
JJ/JJ by Richard Nixon

▲
JJ/RB by Richard Nixon

▲
JJ/N by Richard Nixon

▲
JJ/V by Richard Nixon

▲
RB/RB by Richard Nixon

▲
RB/N by Richard Nixon

▲
RB/V by Richard Nixon

▲
N/N by Richard Nixon

▲
N/V by Richard Nixon

▲
V/V by Richard Nixon
word pairs for John F Kennedy

▲
JJ/JJ by John F Kennedy

▲
JJ/RB by John F Kennedy

▲
JJ/N by John F Kennedy

▲
JJ/V by John F Kennedy

▲
RB/RB by John F Kennedy
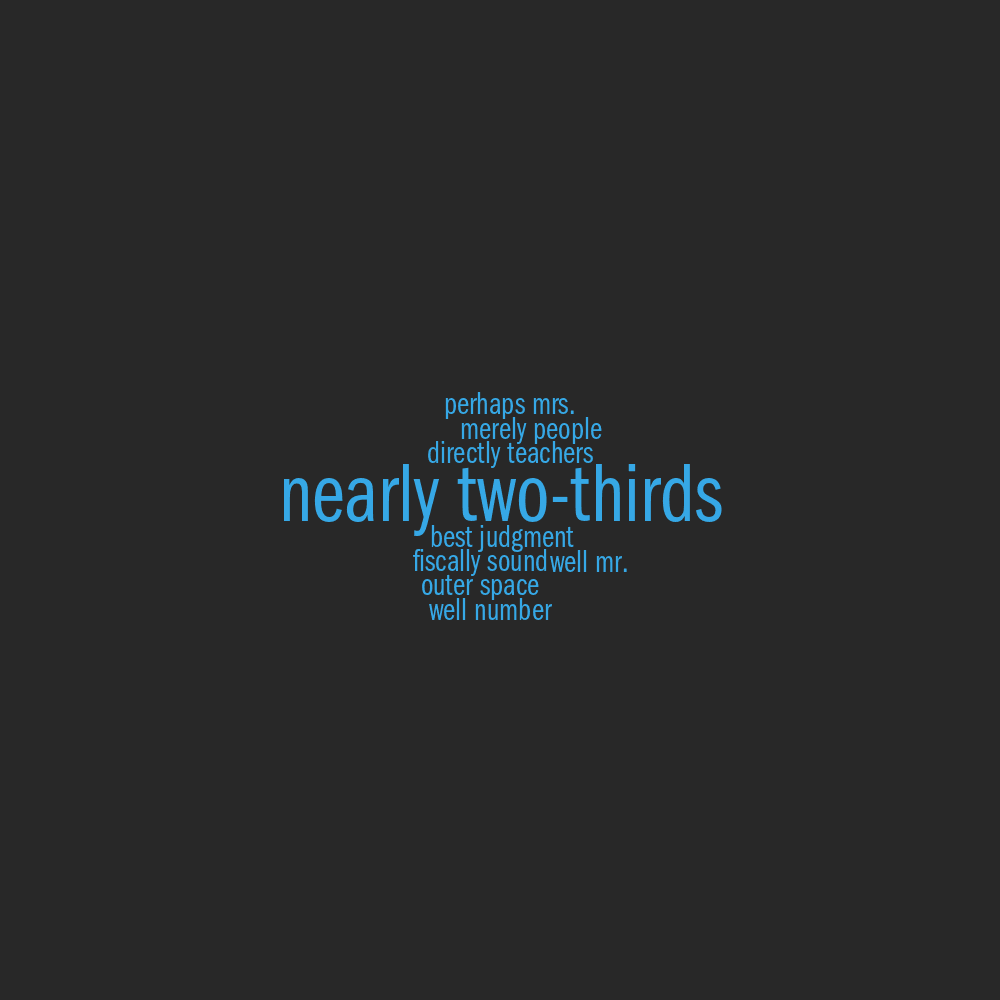
▲
RB/N by John F Kennedy

▲
RB/V by John F Kennedy

▲
N/N by John F Kennedy

▲
N/V by John F Kennedy

▲
V/V by John F Kennedy
Downloads
Debate transcript
Parsed word lists and word clouds (word lists, part of speech lists, noun phrases, sentences) (word clouds)
Raw data structure
Please see the methods section for details about these files.