Word Analysis of 2008 U.S. Presidential Debates
Obama vs. McCain / Biden vs. Palin
Methods
Transcript Preparation
Debate transcripts were downloaded from CNN. The transcript was examined for any inline advertisements from the CNN webpage and for links to other materials. If found, those were removed.
Any markup by the transcriptionist (e.g. (sic), [mispronunciation]) were removed.
Speaker Identification
The start of a speaker's section is indicated in the transcript by a leading SPEAKER_NAME: tag (e.g. OBAMA:, MCCAIN:, etc).
For each debate, the section of the transcript for each of the participants was extracted using the speaker tag. The moderator's contribution was discarded.
Raw transcript portions for a given speaker are found in (SPEAKER.txt) files in the debate parsed file archive. You can download the debate archive from the results page for each debate.
Sentence Identification
For each speaker, their transcript portion was divided into individual sentences. Sentences were extracted using the period (.) as a delimiter. In some cases, words such as "No.2" incorrectly split a sentence. This was rare and not corrected. Sentence files (one sentence per line) are found in (SPEAKER.sent.txt).
Punctuation and Stop Word Removal
All words in the sentence file were stripped of leading (e.g. quotes) and trailing punctuation (e.g. semicolons, periods). Possessives wree de-stemmed (e.g. Obama's became Obama). Sentences with stripped punctuation are found in (SPEAKER.sent.np.txt).
After removing punctuation, all stop words (list) were removed, with the result saved in (SPEAKER.sent.np.ns.txt). This list of stop words includes words that are not typically considered as stop words, such as "going" and "also". I chose to remove these because they contributed heavily to the tag clouds (see below), but did not add any meaning.
Part of Speech Tagging
The Brill tagger was used to identify parts of speech and the output was stored in (SPEAKER.tag.txt) (list of tags).
The tagger is not 100% accurate. Some words are miscategorized and no attempt was made to fix these errors. A good estimate of accuracy for the tagger is 95-97%.
Chunking — Extracting Noun Phrases
BaseNP Chunker was used to identify noun phrases and the output was stored in (SPEAKER.chunk.txt). Noun phrases in this file are delimited by [ and ].
Noun phrases are extracted to SPEAKER.nphrase.all.txt, with one noun phrase per line.
Noun phrase frequency, length (both total words and unique words) are used in the analysis. Similarity between noun phrases (read below) is used to derive a list of unique concepts.
Noun Phrase Similarity
Two noun phrases are compared using their union and intersection. The union is the number of words in the phrases (words may repeat). The intersection is the number of words that appear in both phrases. Similarity is defined as the ratio intersection/union.
Given a noun phrase, its child is a shorter noun phrase which has the highest similarity ratio. It is possible for a noun phrase to have more than one child, in which case all children have the same similarity ratio with the phrase.
Given a noun phrase, its parent is a longer noun phrase which has the highest similarity ratio. It is possible for a noun phrase to have more than one parent, in which case all parents have the same similarity ratio with the phrase.
In order for a noun phrase pair to be considered for the child/parent relationship, the similarity ratio must be ≥0.2. This cutoff is arbitrary, but a non-zero value is useful to impose a minimum amount of similarity before an association between two noun phrases is made.
For example, the two noun phrases "big green dog" and "small green cat" have a union of 5 (unique words are big, green, dog, small, cat) and an intersection of 1 (one word, green, is found in both), yielding a similarity ratio of 1/5=0.2.
Noun Phrase Trees
For a given speaker, two hierarchical trees of noun phrases are constructed: a top-down tree and a bottom up tree. These noun phrase trees associate a noun phrase with its most similar child or parent noun phrase, where a child noun phrase is one that is shorter, and a parent noun phrase is one that is longer. This association is created using the method described above.
The SPEAKER.nphrasetree.child.txt file, which is the top-down list. Each noun phrase spoken by the candidate appears in this file, along with all its child phrases. Here are two example branches of the noun phrase tree, and its format in the file
a b c d e ---------f------------ ---g---------------------- ... 0 2 1 3 3 tBCNRM6b+qr0eSYyvs5UQg low-level diplomatic talks 1 1 1 2 2 8b1/ZNuvgruxhbZ6L9X3uA low-level talks 2 0 1 1 1 /laZKvGiVT1I3jpS5xlQJA talks ... 0 2 1 3 3 dpQjBR6buAp2v6jmMSMpDA one last point 1 1 1 2 2 7OFOeAZ9BNM4NdysHsBshw one point 2 0 5 1 1 eO5Uqo+BOIX+L+INIyUYuQ point ...
with the fields being
- a — depth of the entry in the tree
- b — number of children associated with the noun phrase in this line
- c — number of times the noun phrase appears
- d — number of words in the noun phrase
- e — number of unique words in the noun phrase
- f — a digest of the noun phrase that uniquely identifies it
- g — noun phrase (padded with spaces for higher depths)
For example, consider the noun phrase "low-level diplomatic talks". This noun phrase has two children. Its first child "low-level talks" is at depth=1 (depth of a child is always one more than its parent) and itself has a child "talks". This child phrase is at depth=2, because it is a child of a phrase at depth=1.
Note that a noun phrase may have one or more children. Child phrases are always shorter than their parent.
The bottom-up noun phrase tree can be considered to be the upside-down version of the top-down phrase. In the bottom-up tree, a noun phrase parents are shown. Below is an example of an entry for the "talks" noun phrase.
... 0 3 1 1 1 /laZKvGiVT1I3jpS5xlQJA talks 1 0 1 2 2 BhErVPRfSrokiOLhxNaXuA talks europeans 1 1 1 2 2 8b1/ZNuvgruxhbZ6L9X3uA low-level talks 2 0 1 3 3 tBCNRM6b+qr0eSYyvs5UQg low-level diplomatic talks
This phrase has two parents, each at the same level: "talks europeans" and "low-level talks". These two parents are at the same level because they are of the same length. The "low-level talks" has the parent phrase "low-level diplomatic talks".
Note that a noun phrase may have one or more parents. Parent phrases are always longer than their children.
Every noun phrase has an entry at depth=0 in the tree lists. Then, depending whether it has children (or parents), it is followed by its children (or parents) which appear at depth>1. Noun phrases that have no children (i.e. there are no shorter similar noun phrases in the text) or no parents (i.e. there are no longer similar noun phrases in the text) can be identified by lines that start with "0 0".
Noun phrases without children are listed in SPEAKER.nphrase.nochild.txt. Noun phrases without parents are listed in SPEAKER.nphrase.noparent.txt.
WindBag Index
The purpose of the Windbag Index, created for this analysis, is to measure the complexity of speech. For the present purpose, complex speech is considered to be speech with a large number of concepts and low repetition. The index is low for complex speech and high for verbose and repetitive speech. You do not want to score highly on the Windbag Index, lest you be called a windbag.
The Windbag Index (WI) is defined as a product of terms
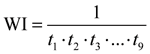
where
- t1 = fraction of words that are non-stop (measures non-filler content)
- t2 = fraction of non-stop words that are unique
- t3 = fraction of nouns that are unique
- t4 = fraction of verbs that are unique
- t5 = fraction of adjectives that are unique
- t6 = fraction of adverbs that are unique
- t7 = fraction of noun phrases that are unique
- t8 = fraction of noun phrases that have no parent
- t9 = ratio of unique noun phrases to unique nouns
Word List Creation
From the tagged file for each candidate, word lists of nouns, verbs, adjectives and adverbs were created. The following tags ((list of tags) were used for each group
- noun — N*
- verb — V*
- verball — V*, MD
- adjective — J*
- adverb — R*
The difference between the verb and verball group is the presence of the modal verb tag (MD) in the verball group.
The results for each word group was saved in SPEAKER.pos.GROUP.txt. In addition to individual groups, a list of words from all four groups was saved in (SPEAKER.pos.all.txt).
Word Pairs List Creation
For each combination (except verball) of part of speech groups listed above, a list of word pairs was created from each sentence. For a given part of speech pair (e.g. noun/verb) all words from the two groups were identified (e.g. all nouns and all verbs) and then all pairwise combinations of words from the two categories were created.
For example, for the tagged sentence
running/VBG president/NN hope/NN talking/VBG tonight/RB
the word categories were
running/VERB president/NOUN hope/NOUN talking/VERB tonight/ADVERB
and the noun/verb pairs were
president running hope running president talking hope talking
Each instance of a word was used to create pairs. Thus, if a word appeared more than once, it generated multiple copies of the same word pair.
For pairs within the same part of speech group (e.g. noun/noun) the same word was not paired with itself.
Unique and Shared Words
Words unique to the candidate were those used by the candidate but not the other. For example, Obama used the word "biodiesel" and McCain did not, so "biodiesel" is a word unique to Obama. On the other hand, both candidates used the word "nuclear", so this falls into the shared group.
In the results section, unique words are sometimes refered to as "exclusive". Care must be taken not to confuse this meaning of unique (i.e. unique to Obama) with the meaning of "distinct". It should be clear by the context which meaning is used. When potential ambiguity arises, I use "exclusive".
Another definition for "exclusive" in the context of words is used to describe words like "but", "except" and "without". When I use exclusive here, I do not mean this. If you are interested in the analysis of these kinds of exclusive words, see the work of Pennebaker.
Words unique to each candidate were saved in (lists/words.SPEAKER.GROUP.txt), for each part of speech GROUP. Words shared by both candidates were saved in (lists/words.both.GROUP.txt).
Tag Cloud Generation
Tag clouds are images of words, with the size of the word in the image proportional to the frequency of occurrence in a text.
The size s(w) of a word (w) in my tag clouds is computed based on
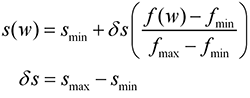
where f(w) is the frequency of the word, fmin and fmax are the smallest (almost always 1) and largest word frequencies, and smin and smax are the smallest and largest desired word sizes. Thus, the least frequent word (almost always, this is a large set of unique words) is size smin and the most frequently used word (or words) are size smax.
Any tag cloud shown in the analysis in which multiple colors are used, is drawn from multiple word lists (each color corresponds to a differnet list). Word sizes are computed realative to usage in each list (i.e. each list has the same smin and smax values, but different fmax). Therefore, absolute word sizes from two different lists cannot be directly compared.
For example, for a tag cloud that shows both nouns and verbs, the most frequent noun and most frequent verb will be of the same size, regardless of their actual frequencies.
Larger words are preferentially placed in the center of the tag cloud, by virtue of the way the tag cloud is formed.
To explore tag clouds, I suggest the most excellent Wordle by Jonathan Feinberg. Shortly, I will be making the word lists from my analysis available in a format that will allow you to create your own Wordles using the Wordle applet.
Data Structure
The raw analysis for each debate results are available for download from the download section on the main page.
The data structure is in XML format. This file is generated automatically from a Perl memory structure, so the format is generic. The inner most block of <item> tags reports individual statistics. Depending on the value of the outer blocks, the statistics are either for word frequencies or sentence lengths.
- n — number of samples (e.g. number of unique words)
- sum — sum of samples (e.g. number of total words)
- min, max, mean, stdev, median, mode — distribution characteristics for the samples
- pNN — NNth percentile
- cNN — NNth cumulative percentile
- cwNN — NNth weighted cumulative percentile
The attributes np, nps and npns refer to all words, stop words and non-stop words, respectively. The "np" stands in this notation indicates that there is no punctuation.
When the item tag attribute is "sentence", the statistics are for sentence length. For example, sentence/npns/palin/mean is the average sentence length for non-stop words.
When the item tag attribute is "word", the statistics are for word frequencies. For example, word/nps/obama/n is the number of word frequencies for Obama's stop word list. Since there is one frequency value per word, this is also the number of unique words. On the other hand, word/nps/obama/sum is the sum of frequencies, or the total number of stop words.
The attribute "pospair" indicates that the statistics are for frequencies of pairs of parts of speech.
The attribute "nphrase" indicates statistics for noun phrases. A variety of noun phrase statistics are available: noparent_X, withparent_X and all_X for noun phrases which have no parent phrase, for those that have a parent phrase, and for all noun phrases. X is one of freq, len or ulen and indicates noun phrase frequency, length (number of words) and unique length (number of unique words).
Finally, the "pos" attribute indicates statistics for individual parts of speech. Within this section of the file, the tag "both" is used for lists of words spoken by both candidate and the tag "all" for words spoken by either candidate. In hindsight, I realize tht I should have used "either" rather than "all".
Weighted Cumulative Distribution
Consider the word list "a b c c d e e e e f f". Here each word is just a letter, for simplicity. The frequency list for these words is 1,1,2,1,4,2 since "a" was seen once, "b" also once, "c" twice, "d" once, and so on. The input to the statistical analysis is the list 1,1,2,1,4,2.
The average of this list is 11/6=1.8 and this is the average word frequency. In other words, on average, each word is used 1.8 times.
The percentile is the value of the list below which a certain percentage of all values fall in a sorted list — 1,1,1,2,2,4. For example, 50% of the values are smaller than 2, so the 50% percentile is 2. Similarly, 83% (5/6) of the values are smaller than 4, so the 83% percentile is 4. For small sets of numbers, as in this example, the percentile is open to ambiguity (e.g. 83% percentile could also be 3.5, since 83% of values are smaller than 3.5). A variety of methods exist to determine percentiles and they converge when the number of values is large. The 50% percentile is also called the median. For word frequencies, the percentile gives the percentage of frequencies smaller than a given frequency. For example, if the 90% percentile of word frequencies is 7.5, then 90% words in the vocabulary of the speaker are found with a frequency of less than 7.5.
Percentile values are identified by key="pNN" attribute in the data structure.
The cumulative distribution values, identified by key="cNN", will correspond to the same values as the percentiles for large lists, but may vary slightly for small lists. The reason for this is the definition of how the percentile is reported by the statistics module I use in my code (Perl's Statistics::Descriptive). It's generally safe to treat "cNN" and "pNN" as the same.
The weighted cumulative distribution, on the other hand, reports what fraction of speech is composed of words below a given word frequency. This is very different than the cumulative distribution (or percentile), which reports the fraction relative to vocabulary words. Consider the example sentence "no no no no no no no no yes yes". 20% (2/10 words) of this sentence is composed of words with a frequency ≤2 (cw20=2), but 50% of the unique words in this sentence (there are only two, "no" and "yes") have a frequency ≤2 (c50=2). Thus think of the cumulative distribution as characterizing the set of unique words and the weighted cumulative distribution as characterizing the actual speech.
Another way to look at the weighted cumulative distribution is as follows. If the 90% weighted cumulative value is 15, for example, then if I take a transcript of a candidate's speech and pick a random word out of it, 90% of the time it will be a word used with a frequency of ≤15.
Atom Feeds and Wordles
You can generate your own tag clouds with Wordle of each of the word lists in the analysis. Wordle accepts Atom feeds as input, and I have made feeds available for each list, which can be accessed from the main page.
The codes for each part of speech in the feed links are noun (n), verb (v), all verbs (including modal verbs) (va), adjective (adj), adverb (adv). The code (all) refers to the union of nouns, verbs, adjectives and adverbs. Other parts of speech, like prepositions and conjunctions, were not considered.
Limitations of Analysis
The analysis presented here is fully automated — there is no manual intervention to transcript processing, with the exception of removal of transcriptionists' notes. Therefore, without any manual intervention, what may appear to be trivial errors propagate due to limitations in parsing.
The accuracy of the part of speech tagger (Brill tagger) is excellent but it does categorize some words incorrectly. Once a word is miscategorized (e.g. Qaeda is a tagged as a verb), it can pollute word lists.
Quirks of speech can affect the analysis significantly. For example, while "Obama" is McCain's top exclusive noun, and one whose frequency outweighs all other nouns by a factor >10, the converse does not apply to Obama. This is because McCain actually uses the words "John" and "McCain" in his speech, and therefore they are not categorized as exclusive to Obama. Had McCain not used those words, the tag cloud of unique nouns by speaker would have a different morphology.
In an interactive debate, where speakers cut each other off, some sentences are fragments and these are not characteristic of the type of sentences that would appear in unfettered speech.
The generation of the noun phrase hierarchy very much depends on the similarity cutoff. This is a value I selected arbitrarily — 0.2 just felt good.
Stop words (these include pronouns, conjunctions and in general parts of speech other than noun, verbs, adjectives and adverbs) are not considered. These compose nearly half of the speech of the candidates and in themselves contain richness of information. For analysis of pronouns, please see the work of Pennebaker.